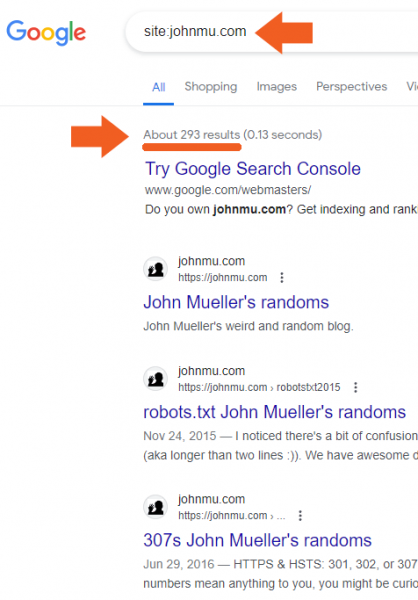
Файл robots.txt Джона Мюллера стал объектом любопытства из-за странных направлений, которые он содержит, и его невероятно огромный размер
Файл robots.txt личного блога Джона Мюллера из Google стал центром интереса, когда кто-то из Reddit заявил, что блог Мюллера пострадал от системы полезного содержимого и впоследствии деиндексирован. Правда оказалась менее драматичной, но все равно немного странной.
Из сообщения X (Twitter) в Subreddit
Сага о robots.txt Джона Мюллера началась, когда кто-то написал об этом на X (ранее известный как Twitter):
.@JohnMu FYI, ваш веб-сайт полностью деиндексирован в Google. Кажется, Google сошел с ума 😱
H/T @seb_skowron & @ziptiedev pic.twitter.com/RGq6GodPsG
— Томек Рудзки (@TomekRudzki) 13 марта 2024 г.
Тогда это было подхвачено на Reddit кем-то после твита, который опубликовал, что веб-сайт Джона Мюллера деиндексирован, написав, что он нарушил алгоритм Google. Но как бы это ни было иронией, но этого никогда не произойдет, потому что нужно всего несколько секунд, чтобы загрузить файл robots.txt веб-сайта, чтобы увидеть, что происходит что-то странное.
Вот верхняя часть файла robots.txt Мюллера, у которой есть пасхальное яйцо с комментариями для тех, кто заглянет.
Первый бит, который можно увидеть не каждый день, это запрет в файле robots.txt. Кто использует файл robots.txt, чтобы сообщить Google не сканировать файл robots.txt?
Теперь мы знаем.
Следующая часть robots.txt блокирует все поисковые системы от сканирования веб-сайта и robots.txt.
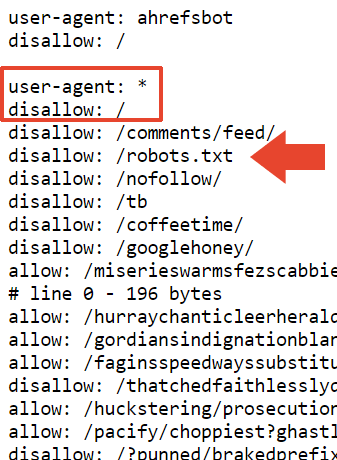
Поэтому это объясняет, почему сайт деиндексирован в Google. Но это не объясняет, почему Bing все еще индексирует его.
Я расспрашивал, и Адам Хамфрис, веб-разработчик и SEO, предположил, что Bingbot, возможно, не посещал сайт Мюллера, поскольку это преимущественно неактивный веб-сайт.
Адам прислал мне сообщение его мысли:
“Агент пользователя: *
Запретить: /topsy/
Запретить: /crets/
Запретить: /hidden/file.htmlВ этих примерах папки и файл в этой папке не найдены.
Он говорит запретить файл robots, который Bing игнорирует, но Google слушает.
Bing проигнорировал бы неправильно реализованных роботов, поскольку многие не знают, как это сделать. “
Адам также предположил, что, возможно, Bing вообще проигнорировал файл robots.txt.
Он объяснил это мне так:
“Так или он решает игнорировать директиву не читать файл инструкций.
Неправильно реализованные указания роботов в Bing, вероятно, игнорируются. Для них это самый логичный ответ. Это”файл маршрутов.”
Файл robots.txt последний раз обновлялся между июлем и ноябрем 2023 года, так что возможно Bingbot не видел последнего файла robots.txt. Это имеет смысл, поскольку система веб-сканирования IndexNow от Microsoft предоставляет приоритет эффективному сканированию. это странное название для папки).
На этой странице практически ничего нет, кроме навигации сайтом и слова Redirector.
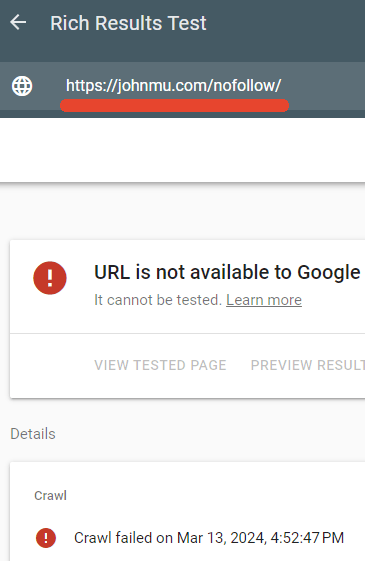
Я проверил, действительно ли robots.txt блокирует эту страницу, и это было.
Тестер Google’s Rich Results не смог просканировать веб-страницу /nofollow/.
См. также: 8 распространенных проблем с файлом robots.txt и способы их решения
Объяснение Джона Мюллера
Мюллера, казалось, порадовало, что так много внимания уделено его robots.txt, и он опубликовал объяснение на LinkedIn относительно происходящего.
Он написал:
“Но что’с файлом? И почему ваш сайт деиндексирован?
Кто-то предположил, что это может быть из-за ссылки на Google+. Это возможно. И вернемся к robots.txt… это’хорошо – Я имею в виду, что это так, как я хочу, и сканеры могут справиться с этим. Или они должны иметь возможность, если они соблюдают RFC9309.”
Далее он сказал, что nofollow в файле robots.txt предназначен просто для того, чтобы предотвратить его индексирование как файл HTML.
Он объяснил:
““запрет: /robots.txt” – это заставляет роботов вращаться по кругу? Это деиндексирует ваш сайт? Нет
В моем файле robots.txt просто много вещей, и он чистее, если он не индексируется вместе с содержимым. Это просто блокирует сканирование файла robots.txt с целью индексирования.
Я мог бы также использовать HTTP-заголовок x-robots-tag из noindex, но таким образом я также имею его в файле robots.txt.”
Мюллер также сказал о размере файла:
“Размер получен из тестов различных инструментов тестирования robots.txt, которые моя команда & Я работал над. В RFC сказано, что сканер должен проанализировать не менее 500 килобайт (бонусные брани первому, кто объяснит, что это за закуска). Вы должны где-нибудь остановиться, вы могли бы создавать бесконечно длинные страницы (и я так и сделал много людей, некоторые даже намеренно). На практике происходит так, что система, которая проверяет файл robots.txt (синтаксический анализатор), где-то вырезает.
Он также сказал, что добавил запрет поверх этой главы в надежде, что это будет воспринято как “общий запрет” но я не знаю, о каком запрете он говорит. Его файл robots.txt содержит ровно 22 433 запрета.
Он написал:
“Я добавил “запрет: /” на вершине этой главы, поэтому, надеюсь, это будет принято как общий запрет. Вполне возможно, что синтаксический анализатор будет обрезан в неудобном месте, например строка из “allow: /cheeseisbest” и он останавливается прямо на “/”, что поставило бы синтаксический анализатор в тупик (и, мелочи! правило разрешения будет заменено, если у вас есть оба “allow: /” и “запретить: /”). Хотя это кажется очень маловероятным.”
Раскрыта тайна деиндексированного веб-сайта
Оказалось, что это не файл robots.txt повлек за собой выпадение сайта Мюллера. Для этого он использовал Search Console.
Мюллер рассказал, что он сделал в следующей публикации на LinkedIn:
“Я воспользовался инструментом Search Console, чтобы что-то попробовать. Я мог бы быстро восстановиться, если нажму правильную кнопку :-).
У Google есть humans.txt. Я действительно не знаю, что я бы положил в свой. У вас есть?”
Веб-сайт Mueller быстро вернулся к индексу поиска.
Снимок экрана, показывающий, что сайт Мюллера вернулся к индексу поиска