
Узнайте, как компании внедряют инициативы маркировки содержимого, чтобы помочь пользователям различать содержимое, созданное людьми, от искусственного интеллекта.
Новое масло не является данным или вниманием. Это слова. Отличительной особенностью создания моделей искусственного интеллекта следующего поколения является доступ к содержимому при нормализации вычислительной мощности, памяти и энергии.
Но Интернет уже становится слишком малым, чтобы утолить голод новых моделей.
Некоторые руководители и исследователи говорят, что потребность отрасли в высококачественных текстовых данных может превысить предложение в течение двух лет, что потенциально замедлит развитие искусственного интеллекта.1
Кажется, даже тонкая настройка не работает так хорошо, как просто создание более мощных моделей. Исследование корпорации Майкрософт показывает, что эффективные подсказки могут превзойти точно настроенную модель на 27%.2
Нам было интересно, будет ли будущее состоять из многих маленьких, точно настроенных, или нескольких больших, всеобъемлющих моделей. Кажется, последнее.
Нет стратегии ИИ без стратегии данных.
Желающие более высококачественного содержимого для разработки следующего поколения больших языковых моделей (LLM), разработчики моделей начинают платить за естественное содержание и восстанавливают свои усилия по маркировке синтетических данных.
Для любого создателя содержимого этот новый поток денег может проложить путь к новой модели монетизации содержимого, которая стимулирует качество и делает Интернет лучше.
Автор изображения: Lyna
Развивайте свои навыки с помощью еженедельных экспертных выводов Growth Memo&P;Подпишитесь бесплатно!
KYC: AI
Если контент — это новая нефть, то социальные сети — это нефтяные вышки. Google инвестировал 60 миллионов долларов в год в использование содержимого Reddit для обучения своих моделей и показа ответов Reddit в верхней части поиска. Пенни, если вы спросите меня.
Генеральный директор YouTube Нил Мохан недавно направил OpenAI и другим разработчикам моделей четкое сообщение о том, что обучение на YouTube запрещено, защищая огромные запасы нефти компании.
The New York Times, которая сейчас ведет судебный процесс против OpenAI, опубликовала статью, в которой утверждается, что OpenAI разработал Whisper для обучения моделей стенограммам YouTube, а Google использует содержимое всех своих платформ, таких как Google Docs и Обзоры Карт, чтобы научить их модели AI.
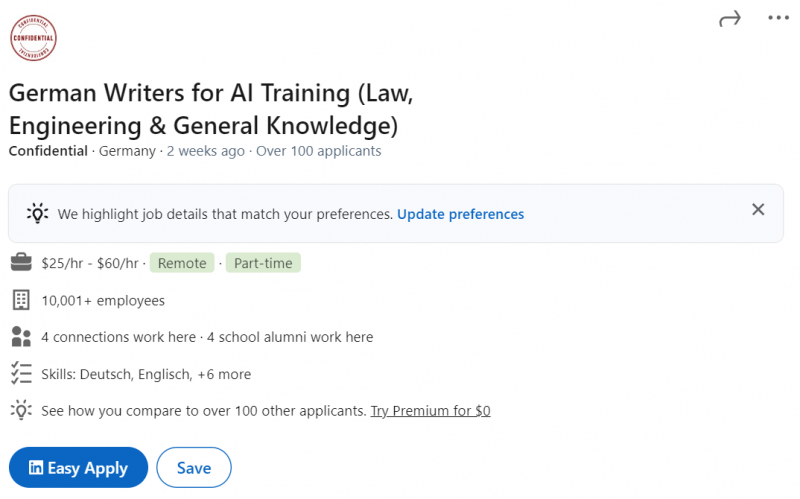
Поставщики генеративных данных AI, такие как Appen или Scale AI, набирают (людей) авторов для создания контента для обучения модели LLM.
Не ошибайтесь, писатели’не богатеют, сочиняя для ИИ.
За 25–50 долларов США в час авторы выполняют такие задачи, как ранжирование ответов ИИ, написание кратких рассказов и проверка фактов.
Кандидаты должны иметь степень доктора философии. или степень магистра или сейчас учатся в колледже. Очевидно, что поставщики данных ищут экспертов и “хороших” писатели. Но первые признаки многообещающие: написание для ИИ можно монетизировать.

Автор изображения: Кевин Индиг
Автор изображения: Кевин Индиг
Разработчики моделей ищут хорошее содержимое в каждом уголке Интернета, а некоторые с удовольствием его продают.
Контент-платформы, такие как Photobucket, продают фотографии от пяти центов до одного доллара за штуку. Короткие видеоролики могут стоить от 2 до 4 долларов; более длинные фильмы стоят от 100 до 300 долларов в час отснятого материала.
Миллиардами фотографий компания добыла нефть на заднем дворе. Какой генеральный директор может выдержать такой соблазн, тем более что монетизация контента становится все труднее и труднее?3
С бесплатного содержимого:
Издателей давят со многих сторон:
- Мало кто готов к смерти посторонних файлов cookie.
- Социальные сети посылают меньше трафика (Meta) или ухудшают качество (X).
- Большинство молодых людей получают новости из TikTok.
- SGE маячит на горизонте.
По иронии судьбы, лучшая маркировка содержимого искусственного интеллекта может помочь разработке LLM, поскольку легче отделить естественное содержимое от синтетического.
В этом смысле разработчики LLM заинтересованы в маркировке AI-контента, чтобы они могли исключить его из обучения или правильно использовать.
Маркирование
Поиск слов для обучения LLM – это лишь одна сторона разработки моделей ИИ следующего поколения. Другой – маркировка. Разработчикам моделей нужна маркировка, чтобы избежать краха модели, а обществу это нужно как щит от фейковых новостей.
Новое движение меток искусственного интеллекта растет, несмотря на то, что OpenAI отказалось от водяных знаков из-за низкой точности (26%). YouTube, Meta и TikTok) заставляют пользователей маркировать содержимое искусственного интеллекта. с подходом кнута/пряника.
Google использует двойной подход для борьбы со спамом искусственного интеллекта при поиске: показывая на заметном месте форумы, такие как Reddit, содержимое которых, скорее всего, создано людьми, и наказание.
От&AIefciency:
Google показывает больше содержимого из форумов в результатах поиска, чтобы уравновесить содержимое ИИ. Верификация – это лучший водяной знак ИИ. Несмотря на то, что Reddit не может запретить людям использовать искусственный интеллект для создания публикаций и комментариев, шансы ниже двух вещей, которых нет в поиске Google: модерирование и карму.
Да&Content Goblins уже нацелились на Reddit, но большинство из 73 миллионов ежедневных активных пользователей дают полезные ответы.1 Модераторы содержимого наказывают за спам запретами или даже изгнаниями. Но самым мощным фактором качества на Reddit является Karma, “оценка репутации пользователя’, отражающая их вклад в сообщество.” Благодаря простому голосованию «за» или «против» пользователи могут получить авторитет и надежность, две неотъемлемых составляющих систем качества Google~~~~~~
Google недавно объяснил, что ожидает, что продавцы не будут удалять метаданные ИИ из изображений с помощью протокола метаданных IPTC.
Если изображение имеет тег вроде compositeSynthetic, Google может обозначить его как “создано ИИ” где угодно, не только в магазинах.5 Наказание за удаление метаданных ИИ непонятно, но я представляю это как наказание за ссылку.
IPTC – это тот же формат, который Meta использует для Instagram, Facebook и WhatsApp. Обе компании предоставляют метатеги IPTC любому содержимому, поступающему от их собственных LLM. Чем больше производителей инструментов искусственного интеллекта придерживаются тех же указаний по обозначению и тегированию содержимого искусственного интеллекта, тем надежнее системы обнаружения работают.
<цитата>
Когда фотореалистичные изображения создаются с помощью нашей функции Meta AI, мы делаем несколько вещей, чтобы убедиться, что люди знают, что задействованный AI, в частности размещаем видные маркеры,& ;nbsp;которые вы видите на изображениях, и оба невидимые водяные знаки& nbsp;и метаданные, встроенные в файлы изображений. Использование невидимых водяных знаков и метаданных улучшает надежность этих невидимых маркеров и помогает другим платформам их идентифицировать.6
Недостатки ШИ-контента незначительны, когда контент выглядит как ШИ. Но когда AI-контент выглядит настоящим, нам нужны метки.
В то время как рекламодатели пытаются избежать внешнего вида искусственного интеллекта, контент-платформы предпочитают его, поскольку его легко распознать.7
Для коммерческих художников и рекламодателей генеративный искусственный интеллект имеет силу значительно ускорить творческий процесс и предоставлять клиентам персонализированную рекламу в больших масштабах. что-то вроде святого Грааля в мире маркетинга. Но есть одна загвоздка: многие модели искусственного интеллекта создают мультяшную плавность, заметные недостатки или то и другое.
Потребители уже отказываются от “вида ИИ” настолько, что невероятная и кинематографическая реклама Super Bowl для христианской благотворительной организации He Gets Us была обвинена в том, что она рождена искусственным интеллектом – хотя фотограф создал ее изображение. 62~
YouTube начал применять новые указания для авторов видео, которые утверждают, что реалистичное искусственное содержимое должно быть обозначено.8
<цитата>
Вызовы, связанные с генеративным искусственным интеллектом, постоянно остаются в центре внимания YouTube, но мы знаем, что искусственный интеллект создает новые риски, которыми плохие игроки могут попытаться воспользоваться на выборах. ИИ можно использовать для создания контента, который потенциально может ввести зрителей в заблуждение – особенно если они не знают, что видео было изменено или создано синтетически. Чтобы лучше решить эту проблему и сообщить зрителям, когда содержимое, которое они просматривают, изменено или синтетическое, мы начнем вводить следующие обновления:
- Раскрытие информации создателям: Творцы должны будут сообщать, когда они’создали измененное или синтетическое содержимое, которое’ реалистичные, включая использование инструментов ИИ. Это будет включать избирательный контент.
- Маркирование:Мы будем обозначать реалистичный измененный или синтетический избирательный контент, не нарушающий нашу политику, чтобы четко указать зрителям, что определенное содержание было изменено или синтетически. Для выбора эта метка будет отображаться как в видеопроигрывателе, так и в описании видео и появляться независимо от автора, политических взглядов или языка.9
Наибольший неизбежный страх — это фейковое содержание ИИ, которое может повлиять на президентские выборы в США в 2024 году.
Ни одна платформа не хочет быть Facebook 2016 года, репутация которого пострадала, что повлияло на курс его акций.
Китайские и российские государственные актеры уже экспериментировали с фейковыми новостями ИИ и пытались вмешаться в выборы на Тайване и будущие выборы в США.10
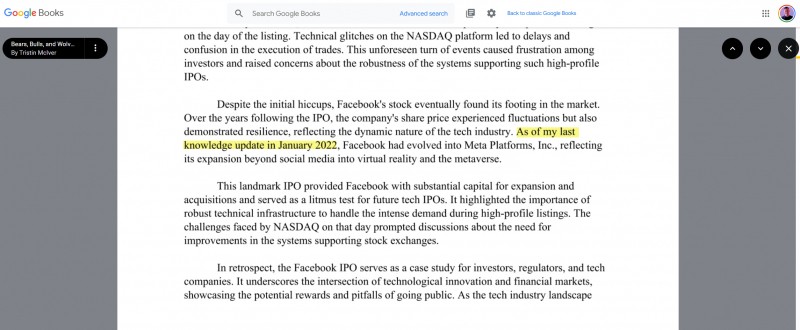
Теперь, когда OpenAI близок к выпуску Sora, создающему гиперреалистичные видео из подсказок, нетрудно представить, как видео с искусственным интеллектом могут создавать проблемы без строгой маркировки. Ситуацию тяжело взять под контроль. Google Books уже содержит книги, которые явно были написаны с помощью или ChatGPT.11
Автор изображения: Кевин Индиг
На вынос
Ярлыки, умственные или визуальные, влияют на наши решения. Они комментируют мир для нас и могут создавать или разрушать доверие. Подобно эвристике категорий в покупках, метки упрощают наше принятие решений и фильтрацию информации.
Из Грязной середины:
<цитата>
Наконец, идея эвристики категорий чисел, на которых клиенты сосредотачиваются для упрощения принятия решений, как мегапиксели для камер, предлагает путь к оптимизации поведения пользователя. Например, магазин электронной коммерции, продающий фотоаппараты, должен оптимизировать свои карты продуктов, чтобы визуально определить приоритет эвристики категории. Конечно, сначала вам нужно понять эвристику в ваших категориях, и они могут отличаться в зависимости от продукта, который вы продаете. Я считаю, что сегодня это то, что нужно для успеха в SEO.
Вскоре ярлыки будут сообщать нам, создан ли контент ИИ или нет. Во время публичного опроса 23 000 респондентов Meta обнаружила, что 82% людей хотят ярлыков на содержание искусственного интеллекта.12 Сработают ли общие стандарты и наказания, еще предстоит выяснить, но срочность есть.
Здесь также есть возможность: ярлыки могут привлечь внимание к авторам-людям и сделать их содержимое более ценным, в зависимости от того, насколько качественным станет содержимое ИИ.
Кроме того, написание для ИИ может являться еще одним способом монетизации контента. Хотя текущие повременные ставки никого не делают богатыми, обучение модели добавляет новую ценность содержимого. Платформы контента могут найти новые источники дохода.
Веб-контент стал чрезвычайно коммерциализированным, но лицензирование искусственного интеллекта может стимулировать авторов вновь создавать качественное содержание и освободить себя от доходов от партнеров или рекламы.
Иногда контраст делает ценность видимой. Возможно, искусственный интеллект все-таки сможет сделать Интернет лучше.
1 Для компаний искусственного интеллекта, которые поглощают данные, Интернет слишком мал
2 Сила подсказки
3 Inside Big Tech's Underground Race to Buy Training Data
4 OpenAI отказывается от инструмента обнаружения текста, сгенерированного искусственным интеллектом
5 IPTC Photo Metadata
6 Обозначение изображений, сгенерированных искусственным интеллектом, в Facebook, Instagram и потоках
7 Как индустрия рекламы делает изображения ИИ менее похожими на ШИ
8 Как мы помогаем создателям раскрывать измененное или синтетическое содержимое
9 Решение дезинформации о выборах, созданной ШИ
10 Китай нацеливается на избирателей США и Тайвань с помощью дезинформации на основе ШИ
11 Google Books индексирует мусор, созданный ШИ
12 Наш подход к маркировке контента, созданного искусственным интеллектом, и манипуляционным медиа