
Эксперты по поисковому маркетингу выразили сомнение, что вероятная утечка данных Google связана с факторами ранжирования
Многие поисковики приходят к выводу, что вероятная утечка данных Google не была утечкой, не содержала секретов алгоритма ранжирования, была устаревшей на пять лет и не показала ничего нового. Хотя это не все думают об этом, специалисты по оптимизации поисковых систем вообще не имеют согласия на что-либо.
Как вчера сообщила SEJ, есть признаки того, что это не дамп данных алгоритма ранжирования, и что есть много вопросов без ответа.
< em>Наше мнение о вероятной утечке:
“На данный момент нет веских доказательств того, что эта “утечка” данные фактически получены из Поиска Google… и никак не связаны с рейтингом веб-сайтов в Поиске Google.”
На данный момент у нас есть больше информации, и многие поисковики говорят, что эта информация не является дампом данных алгоритма.
Некоторые оптимистики призывают к осторожности
В то время как многие в поисковом сообществе быстро восприняли заявления об утечке данных за чистую монету, другие, кто заботится о реальных фактах, предостерегали замедлиться, сначала подумать и быть открытыми ко всем возможностям.
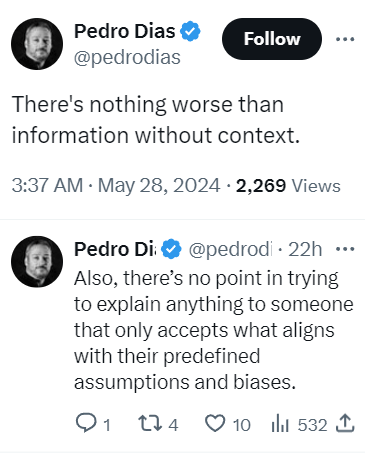
Твит бывшего сотрудника Google Педро Диаса
Райан Джонс был первым, кто выразил скромную оговорку, посоветовав людям в твите смотреть на информацию объективно и без предвзятых идей.
< em>Бывший сотрудник Google Педро Диас написал в Twitter:
“Нет проблем с общими данными. И советуем быть осторожными по поводу толкования некоторых пунктов.”
Педро написал еще один твит, чтобы объяснить, почему он не может комментировать детали:
<цитата>
“Я могу говорить только за себя. Я думаю, вы понимаете, почему я не могу просто исправить конкретные элементы. Я хочу сказать, что нужен контекст и должно быть место для интерпретации.”
Кто-то написал в Twitter, что ответ Педро не добавил ничего к обсуждению.
Педро ответил:
“Я этого не говорил. Все, что я сказал, будьте осторожны, спеша с выводами. Если вы считаете, что это не поможет, извините.”
Позже бывший сотрудник Google написал в Twitter о важности дискуссий:
<цитата>
“Давайте’напомним всем:
– Здорово наводить логические аргументы на дискуссию.
– Ожидать, что все будут покупать мнения без обсуждения, нездорово. Особенно, когда это поступает из источников данных без контекста.~~~~~~~~~~~~~~~~~
Эксперт по поисковому маркетингу Дин Крадденс написал в Twitter:
“Нет ничего, что выдает секретный соус.”
На что ответил бывший сотрудник Google Педро Диас:
<цитата>
“100%
Но последствия этого подпитывают многие фольгированные копейщики и упрощенный поиск, что является неоптимальным.
В конце концов, я считаю, что это больше вредит, чем пользы. Не из-за информации, которую он содержит, а из-за того, как ее’будут создавать и интерпретировать. SEO не покупает его
С днем все больше и больше поисковиков начали открыто сомневаться в утечке. Двадцатилетний эксперт по поисковому маркетингу Тревор Столбер (профиль в LinkedIn) опубликовал свои наблюдения по предполагаемой утечке, указывая на то, что он не купился на это 60
Несколько из того, что он опубликовал на LinkedIn:
- “Это’из устаревшей базы кода (все еще очень интересный – но старый и не используется)
- На самом деле, это не их алгоритм ранжирования, это API, который используется внутри
- Мы уже знали большинство вещей, которые там находятся
- Хорошая документация о рабочем коде определяла бы диапазоны и значения – Я не вижу ничего этого здесь
- Google не&использует DA (Domain Authority) – DA является аналогом PR (Page Rank), который был выдающимся отличием Google – Я не знаю, почему так много внимания уделяется этим нюансам.
Кристин Шахингер, еще один специалист по оптимизации поисковых систем, которого я лично знаю как эксперта, прокомментировала во время этой дискуссии, что информация в так называемой утечке датируется 2019 годом.
“Я читал необработанный дамп, и все они датированы 2019 годом, и с 90% страниц буквально ничего нельзя собрать — Я так согласен. “
Другие участники этой дискуссии открыто поставили под сомнение, действительно ли это была утечка информации, и почти все согласились, что в ней нет ничего нового, и посоветовали, что лучше сосредоточиться на новых обзорах искусственного интеллекта Google, особенно поэтому , что искусственный интеллект не следит за рейтингом факторы.
Это не была утечка?
Из всех людей, занимающихся поисковой системой, отцом современной поисковой оптимизации можно назвать Бретта Табке. Он является основателем конференции по поисковому маркетингу PubCon, а также основателем WebmasterWorld, который в начале SEO был величайшим и важнейшим форумом SEO в мире. Бретт также придумал аббревиатуру SERPs (для страниц результатов поисковой системы).
Бретт посвятил пять часов изучению утечки данных, а затем опубликовал свои наблюдения в Facebook.
Среди его наблюдений (перефразировано):
- Это не утечка
- В нем нет ничего, что напрямую связано с алгоритмом, а скорее это вызовы API.
- Он не нашел ничего, что указывало бы на то, как любые данные можно использовать как часть алгоритма ранжирования.
Эш Наллавалла, корпоративный SEO специалист с более чем 20-летним опытом работы, прокомментировал:
“Как я уже говорил несколько раз, это просто документ API со списком вызовов, а не дамп кода алгоритма. По большей части, мы можем изучить еще немного внутренней терминологии Google.~~~~~~~~~~~~~~~~~~~~~
Утечка данных Google: где факты?
Сообщество поисковых систем осознает, что это была не та утечка данных алгоритма Google, которого некоторые ожидали. На самом деле, это даже не была утечка информации работником Google. И это не секреты алгоритма, но многие соглашаются, что в нем нет ничего нового и что это только отвлечение.