Сжатие данных используется в современном мире повсеместно, практические любое общение двух устройств происходит с сжатием и распаковкой данных для экономии объема передаваемых данных. Например, в HTTP используются протоколы deflate, gzip (deflate с улучшениями). Однако, при некоторых условиях можно достичь куда большего сжатия данных, попробуем разработать такой алгоритм.
Математическое обоснование
Есть теорема, которая описывает сжатие без потерь:
Для любого N > 0 нет алгоритма сжатия без потерь, который:
Любой файл длиной не более N байт или оставляет той же длины, или уменьшает.
Уменьшает некоторый файл длиной не более N хотя бы на один байт.
Докажем полную несостоятельность этой теоремы.
Алгоритм сжатия
А что если использовать хэширование в качестве алгоритма сжатия, например SHA-256?
Во время сжатия будем брать SHA-256 хэш от входного файла и сохранять его в выходной файл вместе с заголовком PK (прямо как в ZIP) и размером исходного файла (Int32, 4 байта).
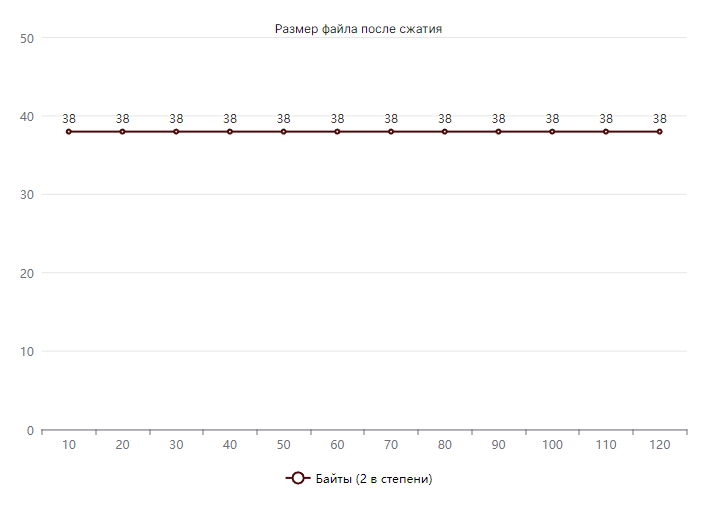
static void Encrypt(string inputPath) { var outputPath = inputPath + ".gigazip"; var inputFile = File.ReadAllBytes(inputPath); using var file = File.Open(outputPath, FileMode.Create); file.Write([(byte)'P', (byte)'K']); //Получаем длину файла в виде байтов (little-endian по умолчанию) var length = BitConverter.GetBytes(inputFile.Length); file.Write(length); file.Write(SHA256.HashData(inputFile)); }Как видно по примеру кода, алгоритм сжатия очень простой и не требует подключения никаких дополнительных библиотек. Архив с сжатыми данными (с учетом метаданных в начале файла) всегда будет весить ровно 38 байт!
График, отображающий отношение размера архива к размеру входных данных
Алгоритм распаковки
Распаковка будет происходить с помощью алгоритма, очень похожего на Proof of work, использующийся в реализации различных криптовалют (Bitcoin, Ethereum).
-
Считываем файл архива, разбираем метаданные
-
Создаем массив длиной N, равной длине исходного файла, (далее выходной файл)
-
Методом перебора выбираем следующий вариант выходного файла
-
Сжимаем файл (берем его SHA-256 хэш), сравниваем его с данными архива
-
Если сжатый файл не совпадает с данными архива, переходим на шаг 3
-
Сохраняем текущий вариант файла как распакованный файл
static void Decrypt(string inputPath) { var bytes = File.ReadAllBytes(inputPath); var length = BitConverter.ToInt32(bytes.Skip(2).Take(4).ToArray()); // 4 байта длины выходного файла var sha256 = bytes.Skip(6).Take(32).ToArray(); // 32 байта сжатых данных const int parallelismDegree = 5; // Будем считать параллельно в 5 потоках var files = Enumerable.Range(0, parallelismDegree).Select(x => { var array = new byte[length]; array[^1] = (byte)(x * (0xFF / parallelismDegree)); // указываем диапазон перебора для каждого из параллельных потоков return array; }) .ToArray(); Run(parallelismDegree, files, sha256, out var targetFile); // в targetFile будут лежать байты выходного файла var outputFileName = inputPath[..^8]; // без .gigazip в конце File.WriteAllBytes(outputFileName, targetFile); }Алгоритм распаковки
private static void Run(int parallelismDegree, byte[][] files, byte[] sha256, out byte[] target) { var targetFile = 0; Parallel.For(0, parallelismDegree, (index, state) => { while (true) { if (state.ShouldExitCurrentIteration) { break; // останавливаемся, если распаковка завершена в другом потоке } var test = SHA256.HashData(files[index]); if (test.FastCompareArrays(sha256)) { targetFile = index; break; } files[index].Increment(); // Выбираем следующий вараинт выходного файла } state.Break(); // Останавливаем вычисления }); target = files[targetFile]; }Другие неинтересные куски кода
internal static class ByteArrayHelpers { [MethodImpl(MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization)] public static unsafe void Increment(this byte[] array) { unchecked // <- отключаем проверку на переполнение типа, 255 + 1 = 0 { var add = true; // получаем указатель на массив, работа с ним быстрее (не происходит проверка рантаймом выхода за пределы массива) fixed (byte* head = array) { for (var i = 0; i < array.Length - 1; i++) { head[i] += *((byte*)(&add)); // reinterpret_cast // если 0, значит переполнили байт, прибавляем 1 к следующему add = head[i] == 0; } } } } [MethodImpl(MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization)] public static unsafe bool FastCompareArrays(this byte[] one, byte[] two) { if (one.Length != two.Length) { return false; } fixed (byte* first = one) { fixed (byte* second = two) { for (var i = 0; i < one.Length; i++) { if (first[i] != second[i]) { return false; } } } } return true; } }Эффективность алгоритма
Эффективность данного алгоритма тем больше, чем больше размер исходного файла.
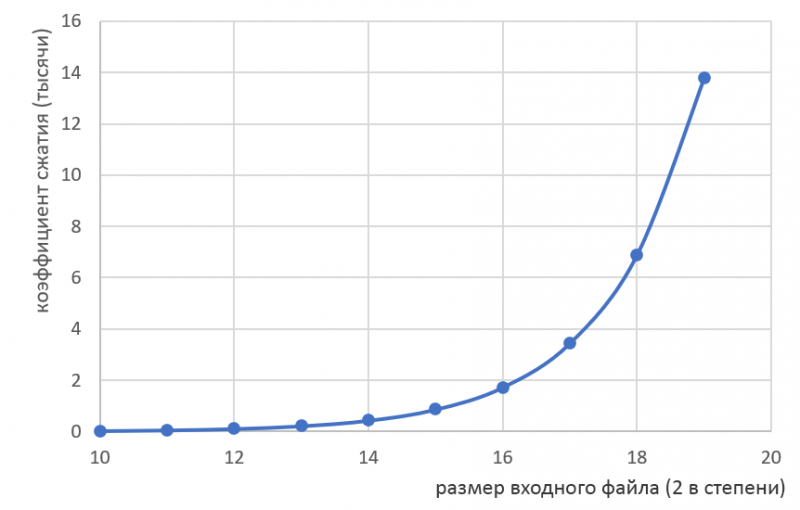
График эффективности алгоритма
Оценка сложности
Сжатие:
-
O(N)– временная сложность -
O(1)– пространственная сложность
Распаковка:
-
O(N^N^N^N...)– временная сложность -
O(N)– пространственная сложность
Недостатки алгоритма
Основной недостаток алгоритма – достаточно медленный процесс распаковки. Например, фильм Shrek 2 (DreamWorks Animation, все права защищены) в формате UHD весом 60ГБ будет распаковываться ориентировочно

лет.
Однако, кажущейся проблемой неоднозначность распаковки (когда одному архиву соответствует несколько выходных файлов) на деле ей не является, что будет рассмотрено в следующем разделе.
Достоинства алгоритма
-
Крайне маленький размер архива
-
Неоднозначность функции хэширования – возможность упаковать в 32 байта несколько входных файлов, к примеру:
-
Shrek 2, Shrek 1 (DreamWorks Animation, все права защищены)
-
Саундтрек к этим фильмам
-
Несколько видеоигр по мотивам этих фильмов
-
Также, при некоторой оптимизации алгоритма (например, использовании вычислений на видеокарте с помощью CUDA) можно уменьшить ожидаемое время распаковки с

до

лет (что уже немалый прогресс).
Заключение
В рамках статьи был предложен инновационный алгоритм сжатия данных, который, надеюсь, в будущем будет использоваться в работе во большинстве крупных IT компаниях.