
Процесс записи хода созвона (фото в цвете)
Приветствую! Меня зовут Григорий, и я главный по спецпроектам в команде AllSee. В современном мире искусственный интеллект стал незаменимым помощником в различных сферах нашей жизни. Однако, я верю, что всегда нужно стремиться к большему, автоматизируя все процессы, которые возможно. В этой статье я поделюсь опытом использования Whisper и ChatGPT для создания ИИ‑секретаря, способного оптимизировать хранение и обработку корпоративных созвонов.
Мотивация
Не только очевидно, но и научно доказано, что использование ИИ в рабочем процессе повышает продуктивность: для белых воротничков до 37%!
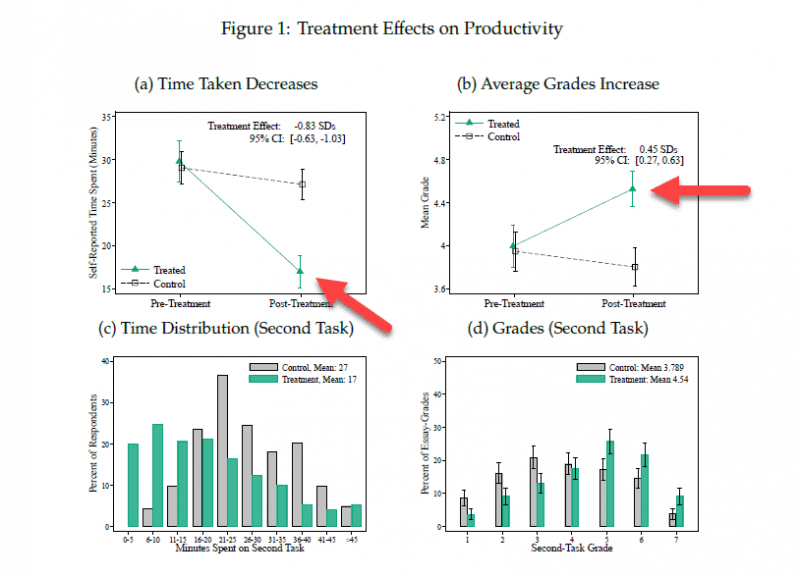
Источник: https://joshbersin.com/2023/03/new-mit-research-shows-spectacular-increase-in-white-collar-productivity-from-chatgpt/
Давайте и мы попробуем «выбить» наши проценты продуктивности, автоматизировав рутинную задачу просмотра записей созвонов.
Какие вводные?
Есть достаточно большая база созвонов, которые иногда приходится пересматривать, расходуя по 30–40 минут на одну запись, а для некоторых видео, особенно для интервью или сбора требований, обработка может занимать даже больше времени, чем сама встреча.
Я хочу повысить эффективность данного процесса, извлекая транскрипции встреч с выделением участников для быстрого просмотра текста, а также уточняя конкретные вопросы у ИИ‑ассистента. Для взаимодействия с нашей системой я буду использовать Telegram‑бота.
Решение
Техническая структура решения включает в себя:
-
Телеграмм бота на базе python‑telegram‑bot
-
Локальный сервер telegram‑bot‑api
-
Локальный API WhisperX
-
Базу данных SQLite
-
Прокси‑сервер
-
ChatGPT API
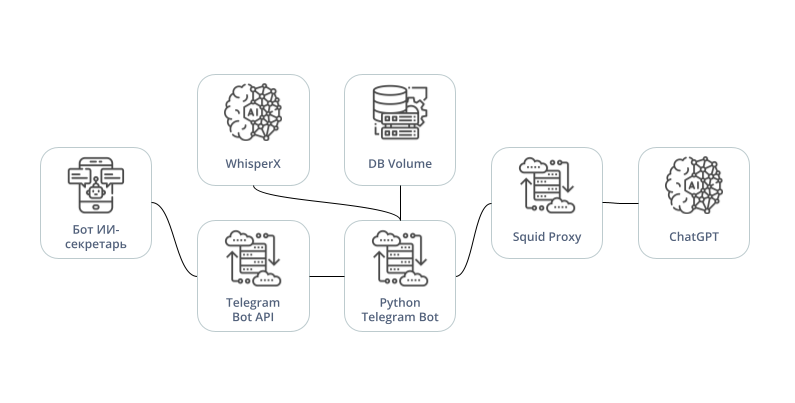
Техническая структура решения
Я опущу многие детали, связанные с UX бота, но постараюсь затронуть важные моменты, с которыми вам точно придётся иметь дело при разработке и интеграции подобного проекта.
Sqiud Proxy
Для работы с ChatGPT API из России нам потребуется настроить proxy‑сервер. Я буду использовать Squid — кэширующий прокси‑сервер для протоколов HTTP, HTTPS, FTP и Gopher.
Инструкция по настройке Squid Proxy
Описывается установка на сервер с OS Ubuntu, но и для других дистрибутивов Linux инструкция будет похожей, отличаясь только используемым менеджером пакетов.
Установка squid
sudo apt update sudo apt-get -y install squidПреднастройка сети
sudo ufw allow squid sudo iptables -P INPUT ACCEPTАктивация сервиса squid
sudo systemctl enable squidНастройка squid
Создаём бекап конфигурации squid и удаляем из оригинального файла всё 8000 строк комментариев.
sudo cp /etc/squid/squid.conf /etc/squid/squid_back.conf sudo grep -v '^ *#|^ *$' /etc/squid/squid.conf > /etc/squid/squid.confОткрываем файл конфигурации squid.
sudo apt-get -y install nano sudo nano /etc/squid/squid.confФайл squid.conf необходимо изменить следующим образом:
... http_access allow localhost acl whitelist src 111.111.111.111 # Добавляем IP адрес нашего основного сервера (нужно указать реальный IP) в список доступа http_access allow whitelist # Разрешаем основному серверу использовать наш прокси http_access deny all ...Перезапуск cервиса squid
Для применения наших настроек достаточно просто перезапустить squid.
sudo systemctl restart squidWhisperX
Для решения поставленной задачи недостаточно просто транскрибировать текст, требуется также решать задачу диаризации: выделять из аудиопотока отдельных дикторов. Задача осложняется тем, что в переговорах и созвонах могут участвовать несколько собеседников, а многие алгоритмы ограничены 2-мя участниками разговора.
На помощь нам приходит WhisperX — «обёртка» над стандартной моделью Whisper для транскрибации, выделения временных меток отдельных слов, а также диаризации до 100 собеседников.
Для интеграции WhisperX в наше решение я написал небольшой FastAPI‑сервер, обрабатывающий входящие аудиофайлы.
Реализация и запуск сервераИмпорты и настройки
import asyncio import os import uuid from dataclasses import dataclass from datetime import datetime from queue import Queue from threading import Thread from typing import Any from fastapi import HTTPException, BackgroundTasks, FastAPI, status, Request from fastapi.middleware.cors import CORSMiddleware from pydantic_settings import BaseSettings from streaming_form_data import StreamingFormDataParser from streaming_form_data.targets import FileTarget from streaming_form_data.validators import MaxSizeValidator import whisperx @dataclass class WhisperXModels: whisper_model: Any diarize_pipeline: Any align_model: Any align_model_metadata: Any class TranscriptionAPISettings(BaseSettings): tmp_dir: str = 'tmp' cors_origins: str = '*' cors_allow_credentials: bool = True cors_allow_methods: str = '*' cors_allow_headers: str = '*' whisper_model: str = 'large-v2' device: str = 'cuda' compute_type: str = 'float16' batch_size: int = 16 language_code: str = 'auto' hf_api_key: str = '' file_loading_chunk_size_mb: int = 1024 task_cleanup_delay_min: int = 60 max_file_size_mb: int = 4096 max_request_body_size_mb: int = 5000 class Config: env_file = 'env/.env.cuda' env_file_encoding = 'utf-8' class MaxBodySizeException(Exception): def __init__(self, body_len: int): self.body_len = body_len class MaxBodySizeValidator: def __init__(self, max_size: int): self.body_len = 0 self.max_size = max_size def __call__(self, chunk: bytes): self.body_len += len(chunk) if self.body_len > self.max_size: raise MaxBodySizeException(self.body_len) settings = TranscriptionAPISettings() app = FastAPI() # noinspection PyTypeChecker app.add_middleware( CORSMiddleware, allow_origins=settings.cors_origins.split(','), allow_credentials=settings.cors_allow_credentials, allow_methods=settings.cors_allow_methods.split(','), allow_headers=settings.cors_allow_headers.split(','), )Логика транскрибации
trancription_tasks = {} trancription_tasks_queue = Queue() whisperx_models = WhisperXModels( whisper_model=None, diarize_pipeline=None, align_model=None, align_model_metadata=None ) def load_whisperx_models() -> None: global whisperx_models whisperx_models.whisper_model = whisperx.load_model( whisper_arch=settings.whisper_model, device=settings.device, compute_type=settings.compute_type, language=settings.language_code if settings.language_code != "auto" else None ) whisperx_models.diarize_pipeline = whisperx.DiarizationPipeline( use_auth_token=settings.hf_api_key, device=settings.device ) if settings.language_code != "auto": ( whisperx_models.align_model, whisperx_models.align_model_metadata ) = whisperx.load_align_model( language_code=settings.language_code, device=settings.device ) def transcribe_audio(audio_file_path: str) -> dict: global whisperx_models audio = whisperx.load_audio(audio_file_path) transcription_result = whisperx_models.whisper_model.transcribe( audio, batch_size=int(settings.batch_size), ) if settings.language_code == "auto": language = transcription_result["language"] ( whisperx_models.align_model, whisperx_models.align_model_metadata ) = whisperx.load_align_model( language_code=language, device=settings.device ) aligned_result = whisperx.align( transcription_result["segments"], whisperx_models.align_model, whisperx_models.align_model_metadata, audio, settings.device, return_char_alignments=False ) diarize_segments = whisperx_models.diarize_pipeline(audio) final_result = whisperx.assign_word_speakers( diarize_segments, aligned_result ) return final_result def transcription_worker() -> None: while True: task_id, tmp_path = trancription_tasks_queue.get() try: result = transcribe_audio(tmp_path) trancription_tasks[task_id].update({"status": "completed", "result": result}) except Exception as e: trancription_tasks[task_id].update({"status": "failed", "result": str(e)}) finally: trancription_tasks_queue.task_done() os.remove(tmp_path)Логика FasAPI
@app.on_event("startup") async def startup_event() -> None: os.makedirs(settings.tmp_dir, exist_ok=True) load_whisperx_models() Thread(target=transcription_worker, daemon=True).start() async def cleanup_task(task_id: str) -> None: await asyncio.sleep(settings.task_cleanup_delay_min * 60) trancription_tasks.pop(task_id, None) @app.post("/transcribe/") async def create_upload_file( request: Request, background_tasks: BackgroundTasks ) -> dict: task_id = str(uuid.uuid4()) tmp_path = f"{settings.tmp_dir}/{task_id}.audio" trancription_tasks[task_id] = { "status": "loading", "creation_time": datetime.utcnow(), "result": None } body_validator = MaxBodySizeValidator(settings.max_request_body_size_mb * 1024 * 1024) try: file_target = FileTarget( tmp_path, validator=MaxSizeValidator(settings.max_file_size_mb * 1024 * 1024) ) parser = StreamingFormDataParser(headers=request.headers) parser.register('file', file_target) async for chunk in request.stream(): body_validator(chunk) parser.data_received(chunk) except MaxBodySizeException as e: raise HTTPException( status_code=status.HTTP_413_REQUEST_ENTITY_TOO_LARGE, detail=f"Maximum request body size limit exceeded: {e.body_len} bytes" ) except Exception as e: if os.path.exists(tmp_path): os.remove(tmp_path) raise HTTPException( status_code=status.HTTP_500_INTERNAL_SERVER_ERROR, detail=f"Error processing upload: {str(e)}" ) if not file_target.multipart_filename: if os.path.exists(tmp_path): os.remove(tmp_path) raise HTTPException( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, detail='No file was uploaded' ) trancription_tasks[task_id].update({"status": "processing"}) trancription_tasks_queue.put((task_id, tmp_path)) background_tasks.add_task(cleanup_task, task_id) return { "task_id": task_id, "creation_time": trancription_tasks[task_id]["creation_time"].isoformat(), "status": trancription_tasks[task_id]["status"] } @app.get("/transcribe/status/{task_id}") async def get_task_status(task_id: str) -> dict: task = trancription_tasks.get(task_id) if not task: raise HTTPException(status_code=404, detail="Task not found") return { "task_id": task_id, "creation_time": task["creation_time"], "status": task["status"] } @app.get("/transcribe/result/{task_id}") async def get_task_result(task_id: str) -> dict: task = trancription_tasks.get(task_id) if not task: raise HTTPException(status_code=404, detail="Task not found") if task["status"] == "pending": raise HTTPException(status_code=404, detail="Task not completed") return { "task_id": task_id, "creation_time": task["creation_time"], "status": task["status"], "result": task["result"] }Dockerfile
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu20.04 RUN apt-get update && apt-get install -y software-properties-common RUN add-apt-repository ppa:deadsnakes/ppa RUN apt-get update && apt-get install -y python3.10 python3.10-venv python3-pip ffmpeg WORKDIR /whisperx-fastapi COPY . . RUN python3.10 -m venv venv RUN /bin/bash -c "source venv/bin/activate && pip install --upgrade pip" RUN /bin/bash -c "source venv/bin/activate && pip install -e ." RUN /bin/bash -c "source venv/bin/activate && pip install -r fastapi/requirements-fastapi-cuda.txt" WORKDIR /whisperx-fastapi/fastapi EXPOSE 8000 CMD ["../venv/bin/uvicorn", "api.app:app", "--host", "0.0.0.0", "--port", "8000"]Запуск сервера
Для развёртывания сервера достаточно скопировать репозиторий, указать в ./fastapi/env/.env.cudaтокен доступа HuggingFace, собрать и запустить контейнер Docker.
sudo docker build -f fastapi/dockerization/dockerfile.fastapi.cuda -t whisperx-fastapi-cuda . sudo docker run -p 8000:8000 --env-file ./fastapi/env/.env.cuda --gpus all --name whisperx-fastapi-cuda-container whisperx-fastapi-cudaTelegram Bot API
Большой проблемой стало ограничение для Telegram‑ботов на обработку файлов более 50мб, что в контексте обработки голосовых и видеозаписей часовых созвонов — смешные цифры.
Данную проблему можно решить достаточно просто: развернуть свой локальный API для Telegram‑бота с помощью telegram‑bot‑api, что позволит нам обрабатывать файлы уже до 2000мб. При этом вся информация бота будет храниться прямо на нашей машине, что позволит быстрее работать с файлами, не дожидаясь получения multipart c сервера.
Как это можно сделать?
На самом деле, очень просто:
apt-get install -y --no-install-recommends build-essential libssl-dev zlib1g-dev git cmake gperf g++ git clone --recursive https://github.com/tdlib/telegram-bot-api.git && cd telegram-bot-api && mkdir build && cd build && cmake .. && cmake --build . --target install cd telegram-bot-api/build ./telegram-bot-api --api-id=${TELEGRAM_API_ID} --api-hash=${TELEGRAM_API_HASH} --local-
TELEGRAM_API_HASH — Hash приложения Telegram
-
TELEGRAM_BOT_TOKEN — Токен бота Telegram
Python Telegram Bot
Ну и, наконец, для обработки запросов от пользователей я использовал python‑telegram‑bot.
Ничего особенного в логике работы я не выделю, поэтому остановимся лишь на интеграции уже готового Telegram‑бота в наше решение.
Развёртывание Telegram-бота
Загрузка репозитория
git clone https://github.com/allseeteam/ai-secretary.gitСборка контейнера
docker build --build-arg HTTP_PROXY=${HTTP_PROXY} --build-arg HTTPS_PROXY=${HTTPS_PROXY} --build-arg NO_PROXY=${NO_PROXY} -t ai-secretary .-
HTTP_PROXY — Адрес прокси-сервера для обхода географических ограничений
-
HTTPS_PROXY — См. HTTP_PROXY
-
NO_PROXY — Адреса, запросы на которые мы будем отправлять без прокси
Создание docker volume для sqlite базы данных
docker volume create ai_secretary_sqlite_dbЗапуск контейнера
docker run -d --network host --volume ai_secretary_sqlite_db:/ai-secretary/database --env-file env/.env --name ai-secretary-container ai-secretary-
TELEGRAM_API_ID — ID приложения Telegram
-
TELEGRAM_API_HASH — Hash приложения Telegram
-
TELEGRAM_BOT_TOKEN — Токен бота Telegram
-
TELEGRAM_BOT_API_BASE_URL — Базовый адрес сервера вашего бота (для локального сервера: http://localhost:8081/bot)
-
OPENAI_API_KEY — Токен OpenAI
-
SQLITE_DB_PATH — Путь по которому мы хотим хранить нашу SQLite базу данных (стандартный адрес: bot/database/ai-secretary.db)
-
TRANSCRIPTION_API_BASE_URL — Базовый адрес сервера для транскрибации (развернуть сервер можно по инструкциям из репозитория, для локального сервера адрес (для данного кейса обязательно при запуске образа указываем –network host): http://127.0.0.1:8000)
Результат
Пример работы с ботом
Как видно, наш ИИ‑секретарь без проблем обрабатывает входящие видеофайлы, а также обсуждает их содержимое с пользователем, учитывая содержание записи и контекст прошлых вопросов.
Заключение
С помощью ChatGPT, Whisper и капли «прогерской магии» нам удалось повысить продуктивность работы с корпоративной базой данных и избавиться от необходимости просматривать часовые видео созвонов, чтобы освежить память перед работой.
А ещё крутая новость для всех любителей «потыкать»: в течение следующей недели бот будет доступен всем желающим для ознакомления и работы. Если у вас возникнут проблемы или предложения по функционалу бота — свободно пишите по контактам в описании.
Всю кодовую базу вы можете найти в репозитории проекта. Если кто‑то вдохновиться проектом и решит модифицировать наши наработки — буду рад принять ваш pull request.
А какие моменты конкретно вашей работы просят автоматизации? Делитесь идеями и мыслями в комментариях — с нетерпением обсужу их вместе с вами. Будьте хорошими людьми, а всё остальное оставьте машинам. Удачи и будем на связи✌️