Сжатие может использоваться поисковыми системами для обнаружения страниц низкого качества. Хотя это малоизвестно, это полезные базовые знания для SEO
Концепция сжимаемости как сигнала качества не широко известна, но оптимистам следует знать об этом. Поисковые системы могут использовать сжимаемость веб-страниц для обнаружения дубликатов страниц, дорвеев с подобным содержимым и страниц с повторяющимися ключевыми словами, что делает эту информацию полезной для SEO.
Хотя следующая исследовательская статья демонстрирует успешное использование функций на странице для обнаружения спама, намеренное отсутствие прозрачности поисковыми системами затрудняет уверенность сказать, применяют ли поисковые системы эту или подобную технику.
Что такое сжимаемость?
В вычислительной технике сжимаемость означает, насколько файл (данные) можно уменьшить в размере, сохраняя при этом важную информацию, как правило, чтобы максимизировать пространство для хранения или разрешить больше данных передавать через Интернет.< /p >
TL/DR сжатие
Сжатие заменяет повторяющиеся слова и фразы более короткими ссылками, уменьшая размер файла в значительной степени. Поисковые системы обычно сжимают проиндексированные веб-страницы, чтобы максимизировать пространство для хранения, уменьшить пропускную способность и улучшить скорость поиска, среди прочих причин.
Это упрощенное объяснение того, как работает сжатие:
- Идентифицировать узоры:
Алгоритм сжатия сканирует текст, чтобы найти повторяющиеся слова, шаблоны и фразы - <сильный>Краткие коды занимают меньше места:
Коды и символы занимают меньше места, чем оригинальные слова и фразы, что приводит к меньшему размеру файла. - Краткие ссылки Используйте меньше битов:
“код” который, в сущности, символизирует замененные слова и фразы, использует меньше данных, чем оригиналы.
Дополнительным эффектом использования сжатия является то, что его также можно использовать для идентификации дубликатов страниц, дорвеев с подобным содержимым и страниц с повторяющимися ключевыми словами.
Исследовательский документ об обнаружении спама
Эта исследовательская статья важна, поскольку ее авторами являются выдающиеся компьютерные ученые, известные своими прорывами в ИИ, распределенных вычислениях, поиске информации и других отраслях.
Марк Найорк
Одним из соавторов научной статьи является Марк Найорк, выдающийся исследователь, имеющий в настоящее время звание выдающегося исследователя в Google DeepMind. Он является соавтором статей для TW-BERT, участвовал в исследованиях по повышению точности использования неявных отзывов пользователей, таких как щелчок, и работал над созданием улучшенного поиска информации на основе ИИ (DSI++: обновление памяти трансформатора новыми документами). ), среди многих других больших прорывов в поиске информации.
Деннис Феттерли
Еще одним из соавторов является Деннис Феттерли, который сейчас является инженером-программистом в Google. Он указан как один из изобретателей в патенте на алгоритм ранжирования, использующий ссылки, и известен своими исследованиями в области распределенных вычислений и поиска информации.
Это только два выдающихся исследователя, указанных в качестве соавторов научной статьи Microsoft 2006 года об идентификации спама с помощью функций содержимого на странице. Среди нескольких особенностей содержимого страницы, которые исследователи анализируют, есть стилистость, которую они обнаружили, можно использовать как классификатор для определения того, что веб-страница является спамом.
Обнаружение веб-страниц со спамом с помощью анализа содержимого
Хотя исследовательская статья была написана в 2006 году, ее результаты остаются актуальными и сегодня.
Тогда, как и сейчас, люди пытались ранжировать сотни или тысячи веб-страниц на основе расположения, по сути, были дублированным содержимым, кроме названий городов, регионов или штатов. Тогда, как и сейчас, специалисты по оптимизации поисковых систем часто создавали веб-страницы для поисковых систем, чрезмерно повторяя ключевые слова в названиях, метаописях, заголовках, внутреннем привязном тексте и содержимом, чтобы улучшить рейтинг.
Раздел 4.6 исследовательской статьи объясняет:
<цитата>
“Некоторые поисковые системы придают больший вес страницам, содержащим ключевые слова запроса несколько раз. Например, для заданного срока запроса страница, содержащая его в десять раз, может иметь более высокий рейтинг, чем страница, содержащая его только один раз. Чтобы воспользоваться преимуществами таких механизмов, некоторые спам-страницы повторяют свое содержимое несколько раз, пытаясь получить более высокие позиции.
В исследовательской статье объясняется, что поисковые системы сжимают веб-страницы и используют сжатую версию для ссылки на оригинальную веб-страницу. Они отмечают, что избыточное количество лишних слов приводит к более высокому уровню сжимаемости. Поэтому они принялись проверить, существует ли корреляция между высоким уровнем сжимаемости и спамом.
Они пишут:
“Наш подход в этом разделе к поиску лишнего содержимого на странице заключается в сжатии страницы; Чтобы сэкономить место и время на диске, поисковые системы часто сжимают веб-страницы после их индексации, но перед добавлением их в кэш страницы.
…Мы измеряем избыточность веб-страниц с помощью коэффициента сжатия, то есть размер несжатой страницы, разделенный на размер сжатой страницы. Мы использовали GZIP для сжатия страниц, быстрый и эффективный алгоритм сжатия.~~~~~~~~~~~~~
Высокая сжимаемость коррелирует со спамом
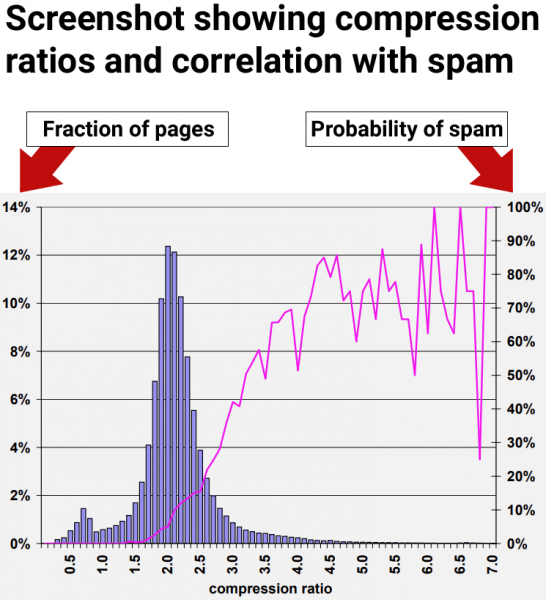
Результаты исследования показали, что веб-страницы с коэффициентом сжатия по крайней мере 4,0, как правило, являются веб-страницами низкого качества, спамом. Однако самые высокие показатели сжимаемости стали менее последовательными, поскольку было меньше точек данных, что затрудняло интерпретацию.
Рисунок 9: Распространенность спама относительно сжимаемости страницы.
Исследователи пришли к выводу:
“70% всех отобранных страниц с коэффициентом сжатия по крайней мере 4,0 было признано спамом.”
Но они также обнаружили, что использование самого коэффициента сжатия все равно приводит к ошибочным срабатываниям, когда страницы, не являющиеся спамом, неправильно идентифицируются как спам:
“Эвристика коэффициента сжатия, описанная в Разделе 4.6, оказалась лучшей, правильно определив 660 (27,9%) страниц спама в нашей коллекции, одновременно неправильно определив 2068 ( 12,0%) всех оцениваемых страниц.
Используя все вышеперечисленные функции, точность классификации после десятикратной перекрестной проверки обнадеживающая:
95,4% наших оцениваемых страниц классифицировано правильно, а 4,6% — неправильно.
Более конкретно, для класса спама 1 940 из 2364 страниц были классифицированы правильно. Для класса не спам 14 440 из 14 804 страниц были классифицированы правильно. Итак, 788 страниц было классифицировано неправильно.”
В следующем разделе описано интересное открытие о том, как повысить точность использования сигналов на странице для идентификации спама.
Взгляд на рейтинги качества
В исследовательской статье рассматривались многочисленные сигналы на странице, включая сжимаемость. Они обнаружили, что каждый отдельный сигнал (классификатор) смог найти спам, но полагаясь на любой один сигнал сам по себе, приводило к обозначению неспамовых страниц как спама, обычно называемых ложными.
Исследователи сделали важное открытие, которое должны знать все, кто интересуется поисковой поисковой системой, а именно то, что использование нескольких классификаторов повысило точность обнаружения спама и уменьшило вероятность ошибочных срабатываний. Не менее важно, сигнал сжимаемости идентифицирует только один вид спама, но не весь диапазон спама.
Вывод состоит в том, что сжимаемость является хорошим способом идентификации одного типа спама, но существуют другие виды спама, которые не перехватываются с помощью этого одного сигнала. Другие виды спама не были перехвачены с помощью сигнала сжимаемости.
Это часть, о которой должен знать каждый SEO и издатель:
“В предыдущем разделе мы представили ряд эвристических методов анализа спам-страниц. То есть мы измерили несколько характеристик веб-страниц и нашли диапазон тех характеристик, которые коррелировали со спамом на странице. Тем не менее, если использовать отдельно, ни один метод не обнаруживает большую часть спама в нашем наборе данных, не обозначая много страниц, не являющихся спамом, как спам.
Например, учитывая эвристику коэффициента сжатия, описанную в разделе 4.6, один из наших наиболее перспективных методов, средняя вероятность спама для коэффициентов 4,2 и выше составляет 72%. Но всего около 1,5% всех страниц попадает в этот диапазон. Это число гораздо ниже 13,8% спам-страниц, которые мы обнаружили в нашем наборе данных.
Поэтому, несмотря на то, что сжимаемость была одним из лучших сигналов для идентификации спама, она все равно не могла выявить полный спектр спама в наборе данных, который исследователи использовали для проверки сигналов.
Об'соединение нескольких сигналов
Вышеприведенные результаты показали, что отдельные сигналы низкого качества менее точны. Потому они тестировали с помощью нескольких сигналов. Они обнаружили, что сочетание нескольких сигналов на странице для обнаружения спама привело к лучшему уровню точности с меньшим количеством страниц, неправильно классифицированных как спам.
Исследователи объяснили, что они проверили использование нескольких сигналов:
Одним из способов сочетания наших эвристических методов является рассмотрение проблемы обнаружения спама как проблемы классификации. В этом случае мы хотим создать модель классификации (или классификатор), которая, если данная веб-страница будет совместно использовать функции страницы, чтобы (мы надеемся, правильно) классифицировать ее в одном из двух классов: спам и не спам.”
Это их выводы относительно использования нескольких сигналов:
<цитата>
“Мы изучили различные аспекты спама на основе содержимого в Интернете, используя набор реальных данных от сканера MSNSearch. Мы представили ряд эвристических методов обнаружения спама на основе содержимого. Некоторые из наших методов обнаружения спама эффективнее других, однако, если их использовать отдельно, они могут обнаружить не все страницы со спамом. По этой причине мы объединили наши методы обнаружения спама для создания высокоточного классификатора C4.5. Наш классификатор может правильно идентифицировать 86,2% всех спам-страниц, одновременно обозначая очень немного законных страниц как спам.
Ключевая информация:
Ошибочное определение “очень мало законных страниц как спама” был значительный прорыв. Важное понимание, которое следует учесть всем, кто занимается SEO, заключается в том, что один сигнал сам по себе может привести к ошибочным срабатываниям. Использование нескольких сигналов повышает точность.
Это означает, что SEO-тесты изолированных рейтингов или сигналов качества не дадут надежных результатов, которым можно доверять для принятия стратегических или бизнес-решений.
Вынос
Мы не знаем наверняка, используется ли сжимаемость в поисковых системах, но это простой в использовании сигнал, который в сочетании с другими можно использовать для перехвата простых видов спама, таких как тысячи дорвеев с названиями городов с подобным содержимым . Однако, даже если поисковики не используют этот сигнал, это показывает, насколько легко уловить такие манипуляции поисковых систем и что сегодня поисковые системы хорошо справятся с этим.< /p>
Вот ключевые моменты этой статьи, о которых следует помнить:
- Дорвеи с повторяющимся содержимым легко обнаружить, поскольку они сжимаются с более высоким коэффициентом, чем обычные веб-страницы.
- Группы веб-страниц с коэффициентом сжатия выше 4,0 были преимущественно спамом.
- Сигналы отрицательного качества, которые сами используются для перехвата спама, могут привести к ошибочным срабатываниям.
- В этом конкретном тесте они обнаружили, что сигналы отрицательного качества на странице улавливают только определенные типы спама.
- При отдельном использовании сигнал сжимаемости улавливает только спам избыточного типа, не обнаруживает других форм спама и приводит к ошибочным срабатываниям.
- Прочесывание сигналов качества улучшает точность обнаружения спама и уменьшает ошибочные срабатывания.
- Сегодняшние поисковые системы имеют более высокую точность обнаружения спама с помощью ИИ, таких как Spam Brain.
Прочитайте научную статью, ссылку на которую есть на странице Марка Найорка в Google Scholar: