Начту с описания проблемы.
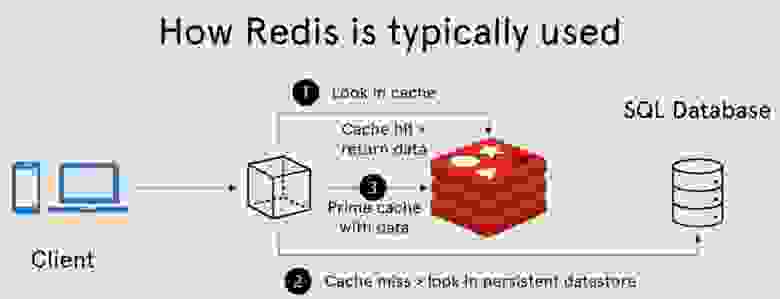
Допустим, вы хотите создать чат и хранить сообщения для него. Вполне возможно, вы можете добавить для этого простую базу данных (БД), такую как MySQL или даже NoSQL.
Однако постоянно извлекать сообщения из БД может быть накладно и долго. Особенно, если в чате есть большое количество неавторизованных пользователей или пользователей с определенными ролями, для которых так же, как и для неавторизованных, нежелательно расходовать ресурсы БД сервера. Кроме того, логично кешировать все сообщения пользователей в чате, где‑то помимо основной базы данных, так как это самая востребованная для получения информация. Логично использовать Redis для кеширования. Мне понравилось видео, которое за 100 секунд объясняет, что такое Redis — Redis in 100 Seconds.
Обычно многие используют Redis как key‑value (dictionary) хранилище. Кстати, видео вскользь объясняет, что Redis — это несколько большее, чем key‑value, как многие привыкли думать.
Задача у нас несколько сложнее, не просто достать сообщения из Redis по ключу, как обычно. Мы еще хотим и доставать сообщения разными гибкими настраиваемыми и кастомными запросами, в зависимости от разных входящих параметров и условий, фильтровать и сортировать… В общем, сделать запросы к Redis почти так же, как мы привыкли взаимодействовать с SQL БД. Логично продублировать работу MySQL сервера для функционала выше и добавить Redis как кэш для сообщений в чате.
Только есть проблема: Redis — NoSQL кэш БД и с довольно урезанным функционалом.
Вы скажете… Мы же можем достать сообщения и их уже отфильтровать на стороне сервера в коде по любой нужной логике. А если сообщений десятки или сотни тысяч?! Это крайне неэффективно.
Гораздо эффективнее было бы уже при запросе к Redis делать так, чтобы он фильтровал, сортировал и выдавал результат, как обычная SQL БД.
Удивлены или сомневаетесь, что такое возможно? Возможно!
Добро пожаловать под кат!
Но… Давайте сначала все равно посмотрим на более полное описание задачи.
При каждой отправке логично отсылать и доставлять сообщение адресатам, например, по веб‑сокету. Также заносить это сообщение в базу данных, чтобы всё это где‑то хранилось. Этого кода не будет в примере, но это важно для общего понимания.
Мы намереваемся разработать на сервере API, которое по нескольким разным входным параметрам выдает разный результат. Если нужно, оно обратится в реальную БД MySQL, а если надо — в кеш в Redis, имитируя Where-подобные запросы, как для SQL. При этом мы избежим перебора, при котором сложность может быть O(n), чего бы очень не хотелось.
К счастью, в Redis есть дополнительный модуль для этого — RediSearch. Изначально он нужен для полнотекстового поиска. Но обо всем по порядку.
Поехали…
В конце статьи будет пример использования транзакций в Redis для batch update. Это важно для понимания всей проблематики. Пример заготовки используемого в статье кода для получения данных доступен на github.
Оговорюсь: я не хочу доказать точку зрения, что хорошо использовать NoSQL кэш в SQL и реляционной парадигме, не думая о модели данных, которая реально подходит для каждого случая и то, что это можно сделать полноценно. Ведь зачем мешать кислое со сладким? Но иногда бывает так, что часть логики SQL модели данных надо повторить в NoSQL для удобства, а также для эффективности работы бизнеса, и этого может требовать кейс, описаный в самом начале.
Здесь и далее я буду использовать JS псевдокод-синтаксис: JS знают все, и этот код можно легко переписать на любые другие языки.
При создании сообщения на сервере напишем код для добавления записи в Redis.
Далее — псевдокод, где {value} — значение для параметра множества возможных значений HSET в Redis.
redisClient.hSet('messages:'+ {id}, { id: {id}, chatId: {chatId}, message: {message}, userId: {userId}, createdAt: {createdAtDt}, data: {dataJson}, read: 0 });Получается набор записей хэшей, которые сгенерируют вызовы hset, где ключ ‘messages:’+{id} — это id сообщения. Значение id может быть id созданного сообщения из БД, ведь оно может появиться до записи сообщения в Redis.
Значения полей объектов в хэшах, которые соответствуют ключам выше, дублируют значения колонок в таблице messages в SQL БД.
Большинство полей в самом объекте должно быть понятно, однако я объясню наименее очевидное.
read — логический флаг. Означает, прочитано ли уже сообщение. По умолчанию считается, что сообщение пока никто не прочитал.
Далее напишем функцию подготовки универсального фильтра для поиска как для SQL, так и для Redis. Объект данных, которые возвращает эта функция, может использоваться как заготовка для Where запроса к SQL БД и для подготовки Where запроса‑близнеца к Redis.
static prepareSearchCriteria = (id, limit, onlyOwn, userId, currentUser) => { ... let searchCriteria; let whereCriteria = { chatId: id }; if (onlyOwn) { whereCriteria['userId'] = currentUser.id; } else if (userId !== null && userId !== undefined) { whereCriteria['userId'] = userId; } searchCriteria = { where: whereCriteria, limit: limit, order: [['createdAt', 'DESC']] } return searchCriteria; }Объясню неочевидное.
Строка 8. Если onlyOwn == true, то этот параметр имеет более высокий приоритет над остальными для выборки, и сообщения для себя надо достать в первую очередь.
Строка 15. Формируем объект searchCriteria, на основе которого вырастет дальнейший запрос для SQL и Redis.
Прежде чем перейдем непосредственно к получению сообщений, я настоятельно рекомендую ознакомиться с RediSearch, хотя бы поверхностно, если вы не знакомы — здесь и здесь.
Забегая вперед: почему RediSearch, а не другой модуль, например RedisJSON? RediSearch может делать полнотекстовый поиск. Также RediSearch может обрабатывать JSON-структуры.
Получение данных с RediSearch ощутимо быстрее, чем с помощью команды Redis — SCAN и тем более KEYS. График сравнения с redis SCAN в примерах выше можно посмотреть здесь. Один поиск у SCAN занял 10 секунд, а RediSearch — 40 мс.
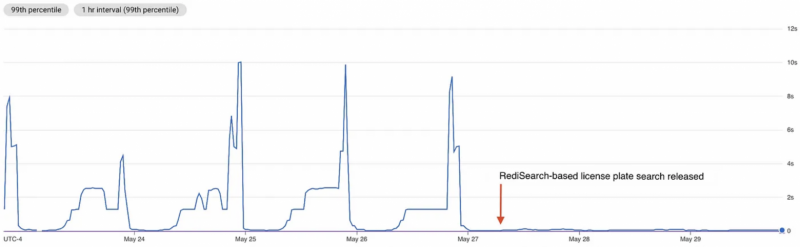
Данные достаются по индексу, возможна высокооптимизированная выдача и никаких O(n):) А при определенных форматах структур данных для поиска (в том числе и наш случай) и шаблона для scan нельзя гарантировать, что удастся избежать перебора.
Теперь настроим RediSearch так, чтоб он справлялся с запросом, который мы сформировали выше. Сначала надо в RediSearch создать индекс для поиска на нужные поля и их типы командой FT.CREATE.
const { SchemaFieldTypes } = require('redis'); static async initialize() { await redisClient.connect(); try { await redisClient.ft.create('idx:messages', { userId: SchemaFieldTypes.NUMERIC, chatId: SchemaFieldTypes.NUMERIC, userId: SchemaFieldTypes.NUMERIC, message: SchemaFieldTypes.TEXT, ... }, { ON: 'HASH', PREFIX: 'messages' }); } catch (e) { if (e.message === 'Index already exists') { console.log('Index exists already, skipped creation.'); } else { // Something went wrong, perhaps RediSearch isn't installed... console.error(e); process.exit(1); } } }Команда JS redisClient.ft.create вызывает команду FT.CREATE из Redis, а команда redisClient.ft.search — команду FT.SEARCH соответственно.
Перейдем непосредственно к самому получению сообщений из комнат чата.
Далее приведена развилка кода, чтобы было понятно, насколько близко и почти одинаково идет получение по разным веткам для SQL БД и для Redis.
Давайте допустим, что функция messages() завязана на REST запрос:
POST /chat/{id}/messages
Body { limit: { Limit сообщений – опционально }, onlyOwn: {Логический флаг, только ли сообщения для текущего пользователя – если true то приоритет в выборке над остальными опциональными полями}, userId: {id пользователя для которого достать сообщения – опционально} }Здесь не GET, а POST, потому запрос может менять состояние данных в БД и Redis, это увидим далее.
В примере приведена верхнеуровневая функция получения сообщений, которая подготавливает запрос, если случай для SQL БД и для Redis. Опустим подробности, их можно посмотреть в примере на github. Скажу лишь, что в примере мы используем Redis для всех ролей, которые не принадлежит конкретному типу.
static messages = async (req, res) => { ... let searchCriteria = ChatController.prepareSearchCriteria(id, limit, onlyOwn, userId, currentUser); ... let messages; if (currentUser.typeId == RolesEnum.API) { //code for fetching from SQL DB ... messages = ...; } else { //code for fetching from Redis ... messages = ...; } .... }Теперь рассмотрим Redis; функционал более интересный.
static handleRedisReadMessages = async (searchCriteria, currentUser) => { let whereCriteria = searchCriteria.where; let redisArrParams = []; let redisStrParams = ""; redisArrParams = ChatController.prepareRedisSearchParams(whereCriteria); redisStrParams = redisArrParams.join(" "); let respMessages = await redisClient.ft.search('idx:messages', redisStrParams, { LIMIT: { from: 0, size: searchCriteria.limit }, SORTBY: { BY: searchCriteria.order[0][0], DIRECTION: searchCriteria.order[0][1] } }); let filteredMessages = ChatController.filterAndMapMessages(respMessages); //transaction part let importMulti = redisClient.multi(); let shouldRedisUpdate = ChatController.isShouldUpdateMessagesInTransaction(respMessages, importMulti, currentUser); ChatController.execTransactionMessagesUpdate(shouldRedisUpdate, importMulti); return filteredMessages; }Смотрим строку 5 и видим ChatController.prepareRedisSearchParams(whereCriteria), где формируется запрос к Redis из универсального запроса, пригодного как для SQL, так и для Redis. Функцию prepareRedisSearchParams можно увидеть ниже.
Строка 6. redisStrParams = redisArrParams.join(” “) — склеиваем то, что получилось, чтобы отправить сообщения для запроса в Redis.
Строка 7. Вызываем уже ft.search, передав ей то, что получилось для универсального запроса, заодно задаем сортировку, в этом примере будет по полю createdAt.
Методы ChatController.isShouldUpdateMessagesInTransaction и ChatController.execTransactionMessagesUpdate относятся к работе с транзакциями, о них поговорим далее отдельно.
Рассмотрим непосредственно саму подготовку параметров для поиска в Redis:
static prepareRedisSearchParams = (whereCriteria) => { let redisSearchParams = ""; redisSearchParams = Object.entries(whereCriteria).map(([key, value]) => { let resParam = null; if (typeof value == "boolean") { let bval = value == true ? 1 : 0; resParam = `@${key}: [${bval} ${bval}]`; } else { resParam = `@${key}: [${value} ${value}]`; } return resParam; }); return redisSearchParams; }Строка 1.
whereCriteria — Мы уже видели этот универсальный объект с параметрами для поиска.
Object.entries(whereCriteria).map(([key, value])
Методично достаем параметры для поиска и формируем из них строки формата @{key}: [{value} {value}]
Два раза написанный value — это не опечатка. Такой синтаксис запросов, даже если точное соответствие.
Для логических типов написана отдельная ветка с кодом. Если бы в запросе были и другие типы, которые требуют особой обработки, то их тоже пришлось бы написать.
Делаем маппинг для удобного отображения возвращаемых сообщений пользователю.
Пример подготовки запроса для RediSearch.
При вызове функции static messages = async (req, res) => {}
Передали набор параметров.
Limit – 5, onlyOwn – false, userId= 7, chatId = 1.
Где: userId – id пользователя, для которого надо делать запрос в БД, chatId — id чата.
Результат работы функции prepareSearchCriteria: searchCriteria = {“where”:{“chatId”:”1″,”userId”:7},”limit”:5,”order”:[[“createdAt”,”DESC”]]}
Результат подготовки строки запроса для RediSearch: redisStrParams = `@chatId: [1 1] @userId: [7 7]`
Транзакции в Redis
Также стоит сказать про транзакции в Redis.
Например, после запроса на получение сообщений мы хотим также и отмечать, какие пользователи еще выбраны, и добавить для этого отдельную колонку в таблице messages, назвав её, например, firstFetchedByUserId. Для простоты этот параметр не введен, а добавлена колонка — прочитано сообщение или нет — read. Хоть это и убогий, ограниченный подход, но он выглядит как подобие работы с реляционными данными:).
Для случая SQL это сделать просто — для ORM Sequalize массовый апдейт по критерию, берем id тех сообщений, что уже прочитали.
await Message.update({ read: true }, { where: { id: idsRead, }, });Для случая Redis такой апдейт тоже делается несложно. Но первое, что предлагает поиск Google для такого решения, — это LUA скрипты. Можно было бы их рассматривать как отдаленных родственников хранимых процедур и функций SQL БД. Только это решение непригодно для случая с репликацией и любых случаев, когда узлов БД больше чем 1, поэтому оно не годится.
Тут на помощь и приходят транзакции Redis.
Сначала определяем, нужно ли обновить сообщения, если хоть одно было прочитано не тем пользователем, который его создал.
static isShouldUpdateMessagesInTransaction = (respMessages, importMulti, currentUser) => { let isUpdate = false; respMessages.documents.forEach(mes => { if ( parseInt(mes.value.userId) != currentUser.id ) { if (!mes.value.read) { importMulti.hSet(mes.id, { "read": 1, }); isUpdate = true; } } }); return isUpdate; }Далее просто выполняем транзакцию, где записи обновляются массово.
static execTransactionMessagesUpdate = (redisUpdate, importMulti) => { if (redisUpdate) { importMulti.exec(function(err,results){ if (err) { throw err; } else { console.log(results); client.quit(); } }); } }Заключение.
Это основное, что я хотел показать; возможно, внимательный читатель заметит, что есть еще и другие модули, вроде RedisJson, но почему я не использовал его для подобной задачи, написал выше.
Еще в RediSearch полно и других команд вроде FT.AGGREGATE…
Цель же статьи — показать, насколько мощны модули, особенно RediSearch, и то, что можно получить видимые профиты, используя их. Например, существенно сэкономить машинные ресурсы, используя правильный подход. Что было и сделано в конкретной бизнес-задаче. Экономия ресурсов была существенной, но еще более существенной была экономия нервных клеток заказчика по сравнению с традиционным способом получения данных из Redis (без использования модулей).
Сам же официальный список модулей с их кратким описанием можно взять на официальном сайте Redis — здесь.