
Узнайте, как использовать векторные базы данных для AI SEO и улучшить свою контент-стратегию. Найдите ближайшее семантическое сходство для вашего целевого запроса с помощью эффективных векторных вставок.
Понимание векторных баз данных
Если у вас есть тысячи статей и вы хотите найти ближайшее семантическое сходство для своего целевого запроса, вы не можете’не создавать векторные встройки для всех них на лету для сравнения, поскольку это очень неэффективно .
Чтобы это произошло, нам нужно было бы сгенерировать векторные встраивания только один раз и хранить их в базе данных, которую мы можем запрашивать и находить статью с ближайшим соответствием.
< p>И именно это делают векторные базы данных: это специальные типы баз данных, которые сохраняют вложения (векторы).
Когда вы посылаете запрос в базу данных, в отличие от традиционных баз данных, они выполняют косинусное сходство и возвращают векторы (в этом случае статьи), ближайшие к другому вектору (в этом случае ключевой фразы), который запрашивается.
Вот как это выглядит:
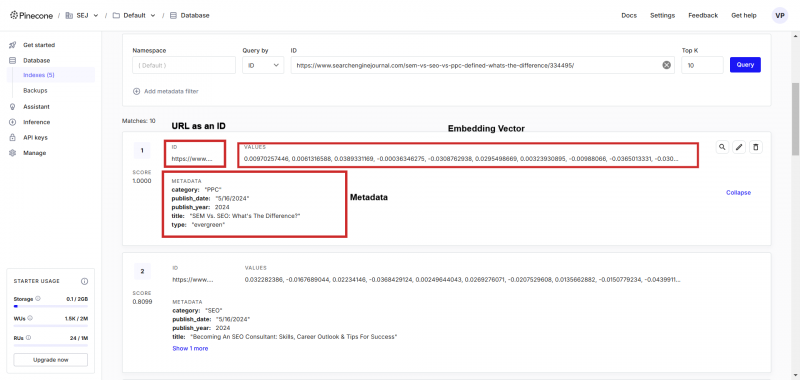
Пример вставки текста в векторную базу данных.
В векторной базе данных вы можете видеть векторы рядом с сохраненными метаданными, к которым мы можем легко спрашивать, используя язык программирования по нашему выбору.
В этой статье мы будем использовать Pinecone из-за его легкости для понимания и простоты использования, но есть и другие поставщики, такие как Chroma, BigQuery , или Qdrant вы можете проверить выход.
Давайте погрузимся.
- 1. Понимание векторных баз данных
- 2. Создайте векторную базу данных
- 3. Экспортируйте свои статьи из CMS
- 4. Вставка встроенных текстов OpenAi в векторную базу данных
- 5. Поиск соответствия статьи для ключевого слова
- 6. Вставка встроенных текстов Google Vertex AI в векторную базу данных
- 7. Поиск соответствия статьи для ключевого слова с помощью Google Vertex AI
- 8. Попробуйте проверить релевантность написания вашей статьи
1. Создайте векторную базу данных
Сначала зарегистрируйте учетную запись в Pinecone и создайте индекс с конфигурацией “text-embedding-ada-002” с ‘косинусом’ как метрика для измерения векторного расстояния. Вы можете назвать индекс как угодно, мы назовем itarticle-index-all-ada‘.
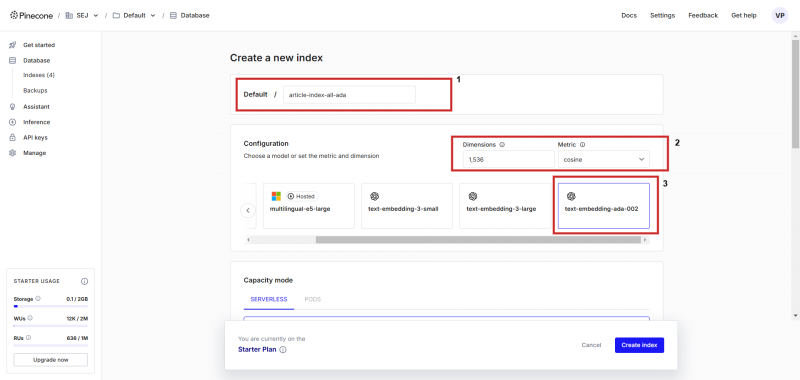
Создание векторной базы данных.
Этот вспомогательный пользовательский интерфейс предназначен только для того, чтобы помочь вам при настройке, если вы хотите сохранить векторное встраивание Vertex AI, вам нужно установить размеры rsquo; до 768 на экране конфигурации вручную, чтобы соответствовать размерности по умолчанию, и вы можете сохранять текстовые векторы Vertex AI (вы можете установить любое значение размерности от 1 до 768 для экономии памяти).
В этой статье мы узнаем, как использовать OpenAi’s ‘text-embedding-ada-002’ и Google’s Vertex AI ‘text-embedding-005’ модели.
После создания нам нужен ключ API, чтобы иметь возможность подключиться к базе данных с помощью URL-адреса хоста векторной базы данных.
Сгенерируйте ключ API
URL-адрес хоста векторной базы данных <стр.>Далее вам понадобится использовать Jupyter Notebook. Если у вас не установлено, следуйте этому руководству, чтобы установить его, а затем запустите эту команду (ниже) в терминале ПК, чтобы установить все необходимые пакеты.
pip установить openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpy
И помните, что ChatGPT очень полезен, когда у вас возникают проблемы при кодировании!
2. Экспортируйте свои статьи из CMS
Далее нам нужно подготовить CSV-файл экспорта статей из вашей CMS.
Поскольку нашей конечной целью является создание внутреннего инструмента связывания, нам нужно решить, какие данные нужно отправлять в векторную базу данных как метаданные. ее с общей структурой RAG путем включения внешних знаний, что поможет улучшить качество поиска.
Например, если мы редактируем статью об “PPC” и хотите вставить ссылку на фразу “Исследование ключевых слов” мы можем указать в нашем инструменте, что “Категория=PPC.” Это позволит инструменту запрашивать только статьи в “PPC” категорию, обеспечивая точные и соответствующие контексту ссылки, или мы можем захотеть сделать ссылку на фразу “последнее обновление Google” и ограничить совпадение только статьями новостей посредством ‘Тип’ и опубликовано в этом году.
В нашем случае мы будем экспортировать:
- Название.
- Категория.
- Тип.
- Дата публикации.
- Год публикации.
- Постоянная ссылка.
- Метаописание.
- Содержание.
Чтобы получить лучшие результаты, мы бы объединили поля заголовка и метаописания, поскольку они лучше всего представляют статью, которую мы можем векторизовать, и идеально подходят для встраивания и внутренних ссылок.
Использование полного содержимого статьи для встраивания может снизить точность и уменьшить релевантность векторов.
Это случается потому, что одно большое встраивание пытается представить несколько тем, рассмотренных в статье одновременно, что приводит к менее сосредоточенному и релевантному представлению. Необходимо применять стратегии разделения на части (разделение статьи на природные заголовки или семантически значимые сегменты), но они не являются предметом этой статьи.
Вот образец файла экспорта, который вы можете загрузить и использовать для нашего примера кода ниже.
2. Вставка встроенных текстов OpenAi&r;
Если предположить, что у вас уже есть ключ OpenAI API, этот код будет генерировать векторные встраивания из текста и вставлять их в векторную базу данных в Pinecone.
импортируйте панды как pd из openai импортируйте OpenAI из шишки импорт Шишка из IPython.display импортировать clear_output # Настройте ключи API OpenAI и Pinecone openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Создание экземпляра клиента OpenAI pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Подключитесь к существующему индексу Pinecone index_name = “индекс-статьи-все-ада” индекс = сосновая шишка.Индекс(название_индекса) def generate_embeddings(текст): “”” Генерирует встраивание для заданного текста с помощью API OpenAI. Возвращает None, если текст недействителен или произошла ошибка. “”” попробуйте: если не текст или не isinstance(text, str): raise ValueError(“Входящий текст должен быть пустой строкой.”) результат = openai_client.embeddings.create( ввод=текст, model=”text-embedding-ada-002″ ) clear_output(wait=True) # Очистить выход для нового отображения if hasattr(result, 'data') и len(result.data) > 0: print(“Ответ API:”, результат) вернуть result.data[0].embedding еще: raise ValueError(“Недействительный ответ от API OpenAI. Данные не возвращены.”) кроме ValueError как ve: print(f”ValueError: {ve}”) возвращения Ни одного кроме исключения как e: print(f”При генерировании вставок произошла ошибка: {e}”) возвращения Ни одного # Загрузите свои статьи с CSV df = pd.read_csv('Образец файла экспорта.csv') # Обработать каждую статью для idx, строка в df.iterrows(): попробуйте: clear_output(wait=true) содержимое = строка[“Содержимое”] вектор = generate_embeddings(содержимое) если вектор не имеет значения: print(f”Пропуск идентификатора статьи {row['ID']} через пустое или недействительное встраивание.”) продолжать index.upsert(векторы=[ ( row['Permalink'], # Уникальный идентификатор вектор, # Встраивание { 'title': row['Title'], 'category': row['Category'], 'тип': строка['тип'], 'publish_date': row['Publish Date'], 'publish_year': row[&Publish Year'] } ) ]) кроме исключения как e: clear_output(wait=true) print(f”Ошибка обработки идентификатора статьи {row['ID']}: {str(e)}”) print(“Встраивание успешно сохранено в векторной базе данных.”)
Вам необходимо создать файл блокнота, скопировать и вставить его туда, а затем загрузить файл CSV ‘Sample Export File.csv’ в той же папке.
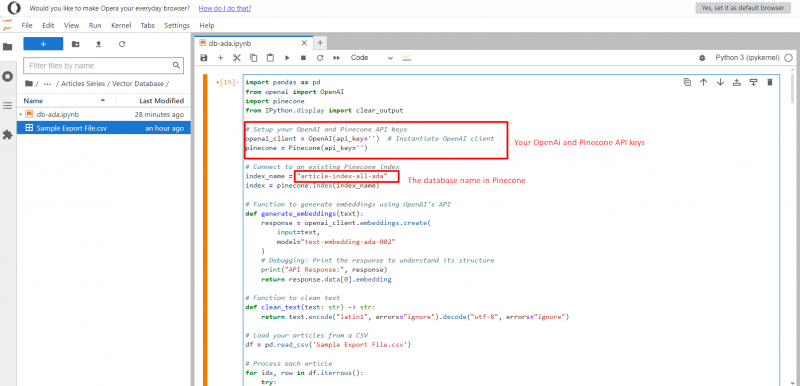
Проект Jupyter.
Окончив, нажмите кнопку «Выполнить», и она начнет отправлять все векторы для встраивания текста в index article-index-all-ada, который мы создали на первом шаге.
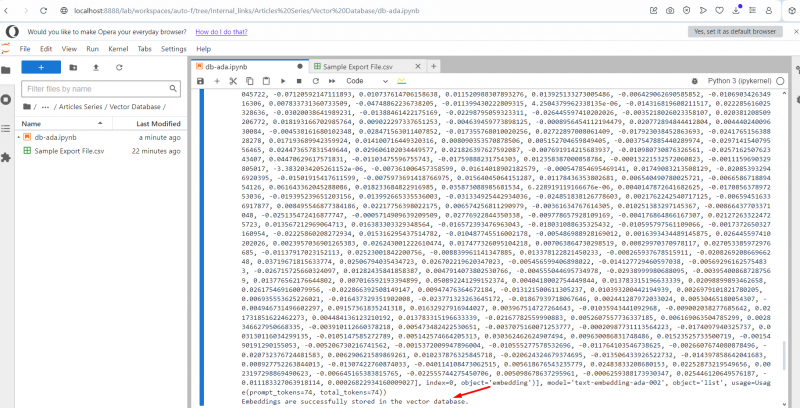
Запуск сценария.
Вы увидите исходный текст журнала встроенных векторов. После завершения в конце появится сообщение об успешном завершении. Теперь просмотрите свой индекс в Pinecone, и вы увидите, что ваши записи там.
3. Поиск соответствия статьи для ключевого слова
Ладно, давайте попробуем найти артикль, который соответствует ключевому слову.
Создайте новый файл блокнота и скопируйте и вставьте этот код.
Это результат, который мы получаем после выполнения кода:
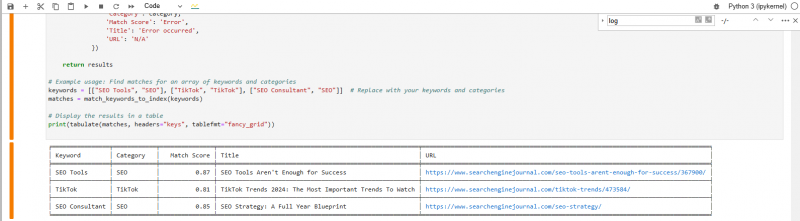
Найти a соответствие ключевой фразе из векторной базы данных
Отформатированная таблица внизу показывает статьи, которые ближе всего соответствуют нашим ключевым словам.
4. Вставка текстовых вставок Google Vertex AI в векторную базу данных
Теперь давайте сделаем то же, но с Google Vertex AI &text;embedding-005’встраивания. Эта модель примечательна тем, что она разработана Google, использует Vertex AI Search и специально обучена выполнять задачи поиска и сопоставления запросов, что делает ее хорошо пригодной для нашего случая использования.
Вы даже можете создать внутренний поисковый виджет и добавить его на свой сайт.
Начните с входа в Google Cloud Console и создайте проект. Затем в библиотеке API найдите Vertex AI API и включите его.
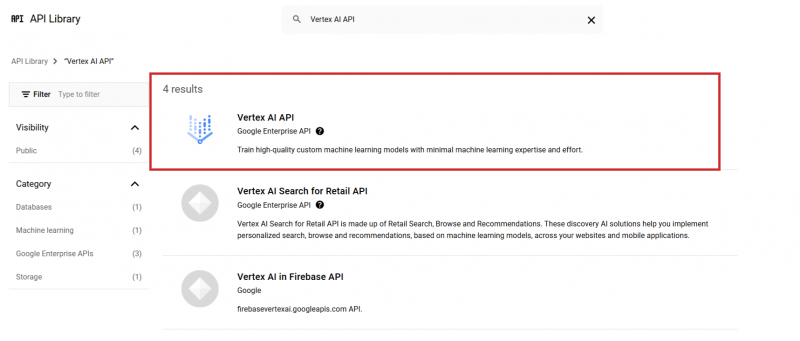
Снимок экрана с Google Cloud Console, декабрь 2024 г.
Настройте свой платежный аккаунт, чтобы иметь возможность использовать Vertex AI, поскольку цена составляет 0,0002 дол. США за 1000 символов (и он предлагает 300 долл. США кредитов для новых пользователей).
После установки необходимо перейти к API Services >
Шаг 1: Создайте аккаунт службы
Шаг 2: Добавьте новый ключ на вкладке «Ключи» аккаунта службы
Шаг 3. Создайте ключ JSON
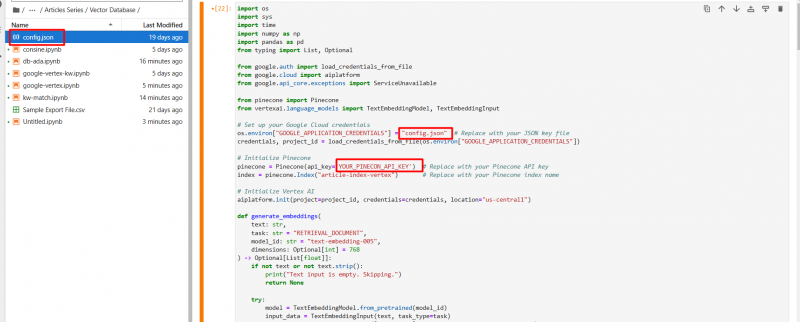
Переименуйте файл JSON на config.json и загрузите его (с помощью значка со стрелкой вверх) в папку проекта Jupyter Notebook.
Снимок экрана с Google Cloud Console, декабрь 2024 г.
На первом шаге настройки создайте новую векторную базу данных под названием article-index-vertex, установив размер 768 вручную.
После создания вы можете запустить этот сценарий, чтобы начать генерировать векторные встраивания из того же файла образца с помощью модели text-embedding-005 Google Vertex AI (вы можете выбрать text-multilingual-embedding-002, если у вас нет -Текст на английском).
импорт ос импорт сист время импорта импортировать numpy как np импортируйте панды как pd после ввода списка импорта, необязательно из google.auth импортировать load_credentials_from_file из google.cloud импорт aiplatform из google.api_core.exceptions импортировать ServiceUnavailable из шишки импорт Шишка из vertexai.language_models импорт TextEmbeddingModel, TextEmbeddingInput # Настройте свои аккаунты Google Cloud os.environ[“GOOGLE_APPLICATION_CREDENTIALS”] = “config.json” # Замените файлом ключа JSON учетные данные, project_id = load_credentials_from_file(os.environ[“GOOGLE_APPLICATION_CREDENTIALS”]) # Инициализация Pinecone pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Заменить своим ключом API Pinecone index = pinecone.Index(“article-index-vertex”) # Замените своим именем индекса Pinecone # Инициализация Vertex AI aiplatform.init(project=project_id, credentials=учетные данные, location=”us-central1″) def generate_embeddings( текст: str, Задание: str = “RETRIEVAL_DOCUMENT”, model_id: str=”text-embedding-005″, размеры: необязательный [int] = 768 ) -> Необязательный [список[float]]: если не текст или не text.strip(): print(“Ввод текста пуст. Пробел.”) возвращения Ни одного попробуйте: модель = TextEmbeddingModel.from_pretrained(model_id) input_data = TextEmbeddingInput(текст, task_type=задание) векторы = model.get_embeddings([входные_данные], выходная_размерность=размеры) векторы возврата[0]. кроме ServiceUnavailable как e: print(f”Сервис Vertex AI недоступен: {e}”) возвращения Ни одного кроме исключения как e: print(f”Ошибка создания вставок: {e}”) возвращения Ни одного # Загрузить данные с CSV data = pd.read_csv(“Образец экспортного файла.csv”) # Замените путь к файлу CSV для idx, строка в data.itrows(): попробуйте: постоянная ссылка = str(row[“Permalink”]) содержимое = строка[“Содержимое”] встраивание = generate_embeddings(содержимое) если не встраивать: print(f”Пропуск идентификатора статьи {row['ID']} из-за пустого или неудачного встраивания.”) продолжать print(f”Встраивание для {постоянной ссылки}: {встраивание[:5]}…”) sys.stdout.flush() index.upsert(векторы=[ ( постоянная ссылка, встраиваемые, { 'category': row['Category'], 'title': row['Title'], 'publish_date': row['Publish Date'], 'тип': строка['тип'], 'publish_year': row[&Publish Year'] } ) ]) time.sleep(1) # Необязательно: спящий режим, чтобы избежать ограничений скорости кроме исключения как e: print(f”Ошибка обработки идентификатора статьи {row['ID']}: {e}”) print(“Все встраивания сохраняются в векторной базе данных.”)
Вы увидите ниже в журналах созданных вставок.
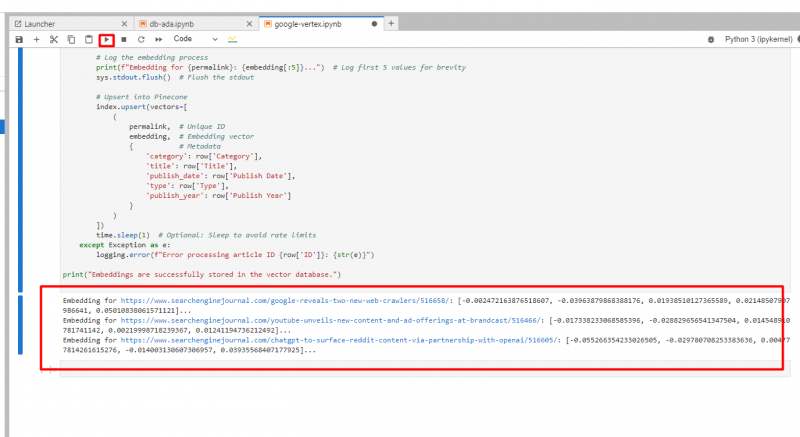
Снимок экрана с Google Cloud Console, декабрь 2024 г.
4. Поиск соответствия статьи для ключевого слова с помощью Google Vertex AI
Теперь давайте сопоставим то же самое ключевое слово с помощью Vertex AI. стараемся выполнить поиск статьи (он же документ), которая лучше всего соответствует нашей фразе.
Это гарантирует, что встраивание фиксирует содержание ключевых слов, что важно для внутреннего связывания, и улучшает релевантность и точность совпадений, найденных в вашей векторной базе данных.
Используйте этот скрипт для сопоставления ключевых слов с векторами.
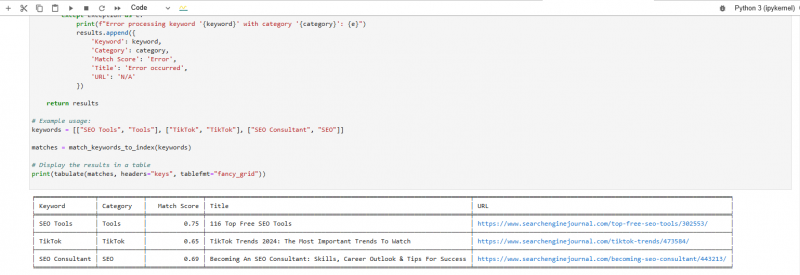
Оценка совпадений ключевых слов создана Модель встраивания Vertex AI
Попробуйте проверить релевантность написания вашей статьи
Подумайте об этом как об упрощенном (широком) способе проверить, насколько семантически подобно ваше написание к ключевому слову head. Создайте векторное встраивание ключевого слова головы и всего содержимого статьи с помощью Vertex AI от Google и вычислите косинусное сходство.
Если ваш текст слишком длинный, вам может понадобиться рассмотреть возможность применения стратегии фрагментации.
Близкий балл (косинусного сходства) до 1,0 (например, 0,8 или 0,7) означает, что вы достаточно близки по этому предмету. Если ваша оценка ниже, вы можете обнаружить, что слишком долгое вступление с большим количеством пустот может повлечь за собой размывание релевантности, а его сокращение помогает повысить ее.
Но помните, что любые внесенные изменения должны иметь смысл также с точки зрения редакции и взаимодействия с пользователем.
Вы даже можете сделать быстрое сравнение, вставив высокопоставленное содержимое конкурента и посмотрев, как вы подошли.
Это поможет точнее согласовать ваше содержимое с целевой темой, что может помочь вам получить лучший рейтинг.
Инструменты, выполняющие такие задачи, уже существуют, но изучение этих навыков означает, что вы можете применить индивидуальный подход, адаптированный к вашим потребностям и, конечно, делать это бесплатно.
Собственные эксперименты и обучение этим навыкам помогут вам опережать AI SEO и принимать обоснованные решения.
<стр.>Я рекомендую вам ознакомиться с этими замечательными статьями: