
Узнайте об эволюции структурированных данных в 2024 году и ее влиянии на SEO, от разработки графов знаний до новых типов данных.
Ландшафт структурированных данных претерпел существенные изменения в 2024 году, вызванный развитием поиска с помощью искусственного интеллекта, растущей важностью машиносчитываемого контента и необходимостью базировать большие языковые модели на фактических данных.
Согласно последнему веб-альманаху HTTP Archive&s;60~/strong>, анализ структурированных данных на 16,9 миллионах веб-сайтов показывает явный отход от традиционного внедрения SEO в более сложную разработку графов знаний, позволяющих системам поиска ШИ.
Хотя в 2023 году Google отказался от определенных расширенных результатов, таких как часто задаваемые вопросы и инструкции, он одновременно ввел беспрецедентное количество новых типов структурированных данных, в частности списки транспортных средств, информацию о курсах, аренде на отдых, страницы профилей и 3D-модели продуктов.
В феврале 2024 года он расширил поддержку вариантов продуктов и GS1 Digital Link, после чего в марте состоялся запуск бета-версии каруселей структурированных данных.
Эта стремительная эволюция указывает на развитие экосистемы, где структурированные данные служат не только видимостью поиска, но и формируют основу для фактических ответов искусственного интеллекта, языковых моделей обучения и улучшенных цифровых продуктов.
Анализ и методология
Статьи, представленные в этой статье, базируются на выпуске 2024 раздела «Структурированные данные» веб-альманаха HTTP Archive’. Годовой отчет анализирует состояние Интернета путем оценки внедрения структурированных данных на 16,9 миллиона веб-сайтов. Эти наборы данных являются открытыми для запроса в BigQuery в таблицах в 'httparchive.all.*'& ;#39;  ;и использует такие инструменты, как WebPageTest, Lighthouse и Wappalyzer для сбора показателей форматов структурированных данных, тенденций внедрения и производительности.
Тенденции внедрения структурированных данных
Анализ показывает убедительный рост основных форматов структурированных данных:
Это широкое внедрение указывает на то, что организации инвестируют в структурированные данные не только для видимости поиска, но и для того, чтобы искусственный интеллект и сканеры могли понимать и улучшать их цифровой опыт.
Графики AI Discovery and Knowledge Graphs
Связь между структурированными данными и системами ИИ развивается сложным образом.
Хотя многие генеративные поисковые системы искусственного интеллекта все еще развивают свой подход к использованию структурированных данных, установившиеся платформы, такие как Bing Copilot, Google Gemini и специализированные инструменты, такие как SearchGPT, уже, кажется, демонстрируют ценность понимания на основе объектов, в частности для локальных запросов и проверки фактов.
Обучение и понимание сущностей
Генеративные поисковые системы искусственного интеллекта учатся на огромных наборах данных, содержащих разметку структурированных данных, влияя на то, как они:
- Распознавать и классифицировать сущности (продукты, места, организации).
- Наземные ответы. Мы видим это в таких системах, как DataGemma, которые используют структурированные данные для обоснования ответов на факты, которые можно проверить.
- Понять связи между различными точками данных. Это особенно очевидно, когда schema.org используется для агрегирования наборов данных из авторитетных источников во всем мире.
- Типы запросов, связанных с процессом, таких как поиск местных предприятий и продуктов.
Этот тренинг определяет, как системы ИИ интерпретируют запросы и отвечают на них, в частности это видно в:
- Локальные бизнес-запросы, где атрибуты сущности соответствуют шаблонам структурированных данных.
- Запросы на продукты, отображающие структурированные данные, предоставленные продавцом.
- Информация на панели знаний, которая соответствует определению сущностей.
Интеграция с поисковыми системами
Различные платформы демонстрируют влияние структурированных данных через:
- Традиционный поиск: Расширенные результаты и панели знаний непосредственно на основе структурированных данных.
- Интеграция поиска AI:
- Bing Copilot показывает улучшенные результаты для структурированных сущностей.
- Google Gemini, отображающий информацию в графе знаний.
- Специализированные механизмы, такие как Perplexity.ai, демонстрирующие понимание сущностей в запросах о местонахождении.
- Последний эксперимент Google’ помощника по продаже AI, интегрированного в поисковую систему для поисковых запросов (Это замечательно! Вот на X, замечено уведомлением о поисковой системе).
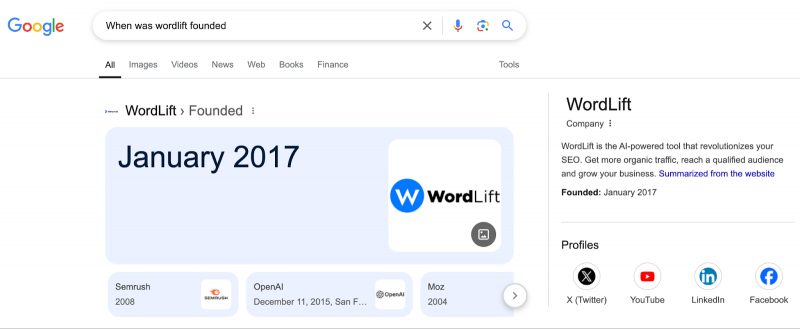
Панель WordLift & Entity Knowledge Graph в Поиске Google – Год основания.
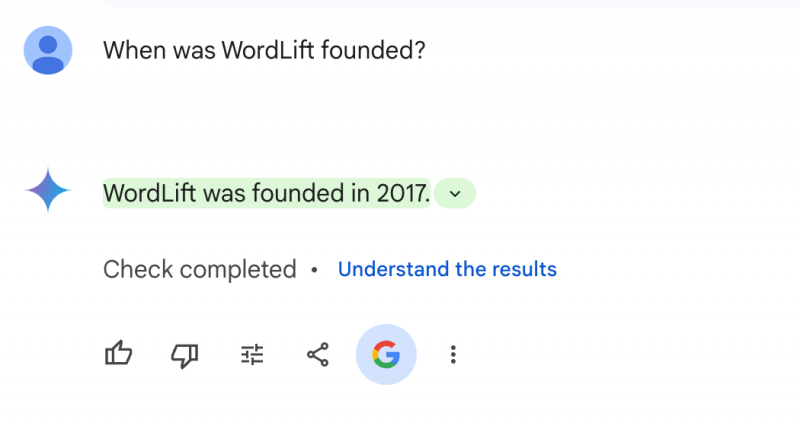
Спрашивая “Когда был основан WordLift?” в Google Gemini.
Вот пример Gemini и Google Search, имеющих один и тот же факт.
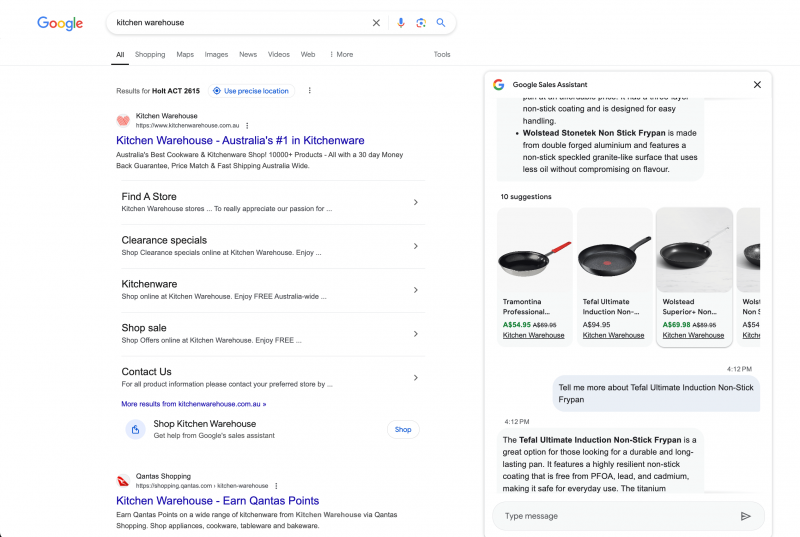
Помощник по продаже AI через ‘магазин’CTA для фирменных ссылок на сайт.
Проверка и проверка данных
Структурированные данные обеспечивают механизмы проверки через:
- Графы знаний: Такие системы, как Google&rsquos Data Commons, используют структурированные данные для проверки фактов.
- Наборы для обучения: Разметка Schema.org создает надежные учебные примеры для распознавания сущностей.
- Конвейеры проверки:Инструменты генерации содержимого, такие как WordLift, используют структурированные данные для проверки результатов ИИ.
Ключевым отличием является то, что структурированные данные не влияют непосредственно на ответы LLM, а скорее формируют поисковые системы ИИ с помощью:
<ол>
Это делает реализацию структурированных данных все более важной для видимости как на традиционных, так и на поисковых платформах на основе ИИ.
Мы вступаем в эту новую эру AI Discovery, инвестиции в структурированные данные больше не касаются только SEO – это’речь идет о создании семантического уровня, позволяющего машинам действительно понимать и точно представлять, кем вы являетесь.
Семантическая эволюция SEO: от структурированных данных до семантических данных
Практика поисковой оптимизации превратилась в семантическую поисковую оптимизацию, выходя за рамки традиционной оптимизации ключевых слов и охватывая семантическое понимание:
Оптимизация на основе сущностей
- Сосредоточьтесь на четких определениях сущностей и связях.
- Реализация комплексных атрибутов сущности.
- Стратегическое использование свойств sameAs для устранения неоднозначности.
Контентные сети
- Разработка взаимосвязанных кластеров контента.
- Четкое указание источника и авторство.
- Определение связей с мультимедиа.
Ключевые шаблоны реализации в JSON-LD
Публикация содержимого
Анализ шаблонов структурированных данных на миллионах веб-сайтов показывает три доминирующие тенденции внедрения для издателей контента. content/uploads/2024/11/viz-12-38.png” alt=”Шаблоны JSON-LD для издателей содержимого “width=”600″ height=”400″ class=”wp-image-532853 size-full” srcset=”https://www.searchenginejournal.com/wp-content/uploads/2024/11/viz- 12-38.png 600w, https://www.searchenginejournal.com/wp-content/uploads/2024/11/viz-12-38-480×320.png 480w, https://www.searchenginejournal.com/wp-content/uploads/2024/11 /viz-12-38-384×256.png 384w” sizes=”(max-width: 600px) 100vw, 600px” loading=”ленивый” >Шаблоны JSON-LD для издателей содержимого.
Структура веб-сайта &
Доминирование WebPage &rar; isPartOf &rar; Веб-сайт (5,8 миллионов) и веб-страница &rar; отдают приоритет четкой архитектуре сайта и навигационным путям.
Обозначение содержимого & Авторитет
Появляются сильные закономерности относительно атрибуции содержимого:
- Статья → автор &rar;
- Статья → издатель &rar;
- Публикация в блоге &rar; автор &rar;
Это внимание к авторству и организационной атрибуции отражает растущую важность сигналов E-E-A-T и авторитета содержимого в алгоритмах поиска.
Интеграция Rich Media
Последовая реализация разметки изображений для типов содержимого:
- Веб-страница → первичное изображение страницы &rar;
- Статья → изображение &rar; ImageObject (806 000)
Высокая частота связей со СМИ указывает на то, что издатели признают ценность структурированного визуального содержимого как для видимости поиска, так и для взаимодействия с пользователем.
Данные свидетельствуют о том, что издатели выходят за пределы базовой SEO-разметки и создают комплексные машиночитаемые графики содержимого, которые поддерживают как традиционный поиск, так и новейшие системы обнаружения искусственного интеллекта.
Местный бизнес & Розница
Анализ внедрения структурированных данных местного бизнеса выявил три критические группы шаблонов, которые доминируют в разметке на основе расположения.
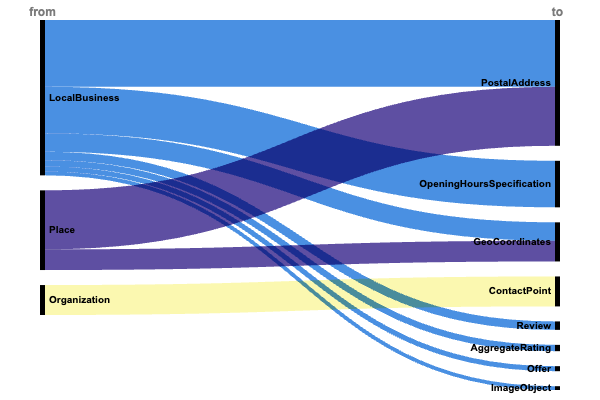
Шаблоны JSON-LD для местного бизнеса и розничной торговли. (Изображение автора, ноябрь 2024 г.)
Местоположение & Доступность (+1,4 миллиона реализаций)
Высокое применение разметки физического расположения демонстрирует ее фундаментальную важность:
- Местный бизнес → адрес &rar; Почтовый адрес (745 000).
- Разместить → адрес &rar; Почтовый адрес (658 000).
- Организация → contactPoint →
- Местный бизнес → Спецификация часов открытия (519 000).
Сильное присутствие этих основных операционных деталей свидетельствует о том, что они являются основными факторами ранжирования для видимости локального поиска.
Географическая точность
Значительное внедрение геокоординат показывает фокус на точном месте:
- Разместить &rar;
- Местный бизнес &rar; Геокоординаты (205 000).
Этот двойной подход к расположению (адрес + координаты) указывает на то, что поисковые системы ценят точное географическое позиционирование для точности локального поиска.
Сигналы доверия
Меньшая, но заметная группа шаблонов сосредотачивается на репутации:
- Местный бизнес → просмотреть &rar; Обзор (94 000)
- Местный бизнес → aggregateRating &rar; Совокупный рейтинг (70 000)
- Местный бизнес → фотографии &rar;rar; ImageObject (42 000)
- Местный бизнес → делает предложение &rar;rar; Предложение (56 000)
Хотя и реже внедряются, эти элементы укрепления доверия создают более богатые местные бизнес-структуры, которые поддерживают видимость поиска и принятия решений пользователями.
Электронная коммерция (расширенный список)
Анализ структурированных данных электронной коммерции обнаруживает сложные модели внедрения, которые сосредоточены на обнаружении продукта и оптимизации конверсии.
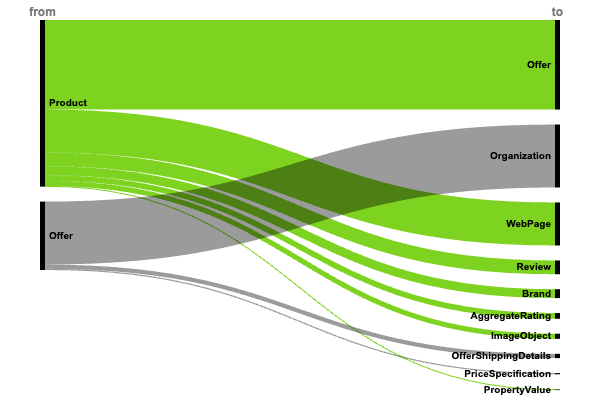
Шаблоны JSON-LD для веб-сайтов электронной коммерции. (Изображение автора, ноябрь 2024 г.)
Информация об основном продукте (+4,7 миллионов реализаций)
Доминирование базовой торговой наценки показывает ее фундаментальную важность:
- Продукт → предлагает &rar;rar; Предложение (3,1 миллиона).
- Предложение → продавец &rar; Организация (2,2 млн.).
- Продукт → mainEntityOfPage &rar; Веб-страница (1,5 миллиона).
Этот высокий уровень введения связей с основными продуктами указывает на их критическую роль в выявлении продукта и видимости продавца.
Доверие & Социальное доказательство
Значительное внедрение разметки, связанной с осмотром:
- Продукт → просмотреть &rar; Обзор (490 000).
- Продукт → aggregateRating &rar; Совокупный рейтинг (201 000).
- Просмотреть → обзорОценка &rar; Рейтинг (110 000).
Значительное присутствие рецензионной разметки свидетельствует о том, что социальные доказательства остаются решающими для конверсии электронной коммерции.
Улучшенный контекст продукта
Реализация богатых атрибутов продукта показывает фокус на подробной информации о продукте:
- Продукт → бренд &rar; Бренд (315 000).
- Продукт → extraProperty &rar; PropertyValue (253 000).
- Продукт → изображение &rar; ImageObject (182 000).
- Предложение → детали доставки &rar;rar; OfferShippingDetails (151 000).
- Предлагать &rar; priceSpecification &rar; Характеристики цены (42 000).
- AggregateOffer → предлагает &rar;rar; Предложение (69 000).
Этот многоуровневый подход к атрибутам продукта создает комплексные сущности продукта, которые поддерживают видимость поиска и принятия решений пользователем.
Будущее
Роль структурированных данных выходит за пределы их традиционной функции как инструмента SEO для создания расширенных фрагментов и специальных функций поиска. В эпоху открытий искусственного интеллекта структурированные данные становятся критически важным фактором для машинного понимания, изменяя, как контент интерпретируется и связывается в Интернете. Это изменение побуждает отрасль к мыслить за пределами ориентированной на Google оптимизации, охватывая структурированные данные как основу семантической компоненты и интегрированной с ИИ сети.
Структурированные данные обеспечивают основу для создания взаимосвязанных машиносчитываемых структур, жизненно важных для новых приложений искусственного интеллекта, таких как разговорный поиск, графы знаний и (Graph) системы генерации с дополненным поиском (GraphRAG или RAG). . Эта эволюция требует двойного подхода: использование эффективных типов схем для получения мгновенных преимуществ от SEO (расширенные результаты) и одновременно инвестирование в комплексные описательные схемы, создающие более широкую экосистему данных.
Будущее — за пересечением структурированных данных, семантического моделирования и систем обнаружения контента, управляемых ИИ. Приняв более целостное представление, организации могут перейти от использования структурированных данных в качестве тактического дополнения к поисковой оптимизации до позиционирования их как стратегического уровня для активизации взаимодействия ИИ и обеспечения возможности поиска на разных платформах.
Благодарность и благодарность
Этот анализ был бы невозможен без преданной работы команды архива HTTP и участников веб-альманаха. Особая благодарность:
<стр.>Полная глава веб-альманаха «Структурированные данные» предлагает еще более глубокое представление о развитии структурированных данных.
По мере того как мы движемся к будущему на базе искусственного интеллекта, стратегическое значение структурированных данных будет расти.