
Все еще актуален robots.txt в эпоху искусственного интеллекта? Узнайте, почему этот файл является решающим для управления сканированием сайта и избегания распространенных ловушек.
Robots.txt только что исполнилось 30 – преодолейте экзистенциальный кризис! Как и многие другие, кто достигает больших 3-0, ему интересно, актуально ли это все еще в современном мире искусственного интеллекта и расширенных алгоритмов поиска.
Спойлер: точно так!
Давайте посмотрим, как этот файл все еще играет ключевую роль в управлении тем, как поисковики сканируют ваш сайт, как правильно его использовать и распространенные подводные камни, которых следует избегать.
Что такое файл robots.txt?
Файл robots.txt предоставляет сканерам, таким как Googlebot и Bingbot, инструкции по сканированию вашего сайта. >
- Какие сканеры имеют/не&разрешено входить?
- Любые ограниченные области (страницы), которые нельзя сканировать.
- Приоритетные страницы для сканирования – через XML-декларацию карты сайта.
Его главная роль — управлять доступом сканера к определенным областям веб-сайта, указывая, какие части сайта “запрещено.” тратят бюджет сканирования на малоценное содержание.
Хотя файл robots.txt управляет сканерами, важно отметить, что не все боты придерживаются его указаний, особенно вредны. Но для большинства легальных поисковых систем соблюдение директив robots.txt является стандартной практикой.
Что содержится в файле robots.txt?
Файлы Robots.txt состоят из строк директив для поисковых систем и других роботов.
Действующие строки в файле robots.txt состоят из поля, двоеточия и значения.
Файлы Robots.txt также обычно содержат пустые строки для улучшения читабельности и комментарии, чтобы помочь владельцам веб-сайтов отслеживать директивы.

Изображение от автора, ноябрь 2024 год
Чтобы лучше понять, что обычно содержится в файле robots.txt и как разные сайты используют его, я просмотрел файлы robots.txt для 60 доменов с высокой долей голоса в области здравоохранения, финансовых услуг, розничной торговли и высокого уровня. тех.
Не учитывая комментарии и пустые строки, среднее количество строк в 60 файлах robots.txt составляло 152.
Большие издатели и агрегаторы, такие как hotels.com, forbes.com и nytimes.com, как правило, имели более длинные файлы, тогда как больницы, такие как pennmedicine.org и hopkinsmedicine.com, обычно имели более короткие файлы. Файлы robots.txt сайтов розничной торговли обычно приближаются к среднему значению 152.
Все проанализированные сайты содержат поля user-agent и disallow в своих файлах robots.txt, и 77% сайтов включили декларацию sitemap с полем sitemap.
Реже использовались поля «разрешить» (используется 60% сайтов) и «задержка сканирования» (используется 20%) сайтов.
<таблица style="border-collapse: collapse; width: 81,7318%;"> <тела>
Robots.txt Синтаксис
Теперь, когда мы рассмотрели, какие типы полей обычно входят в robots.txt, мы можем глубже погрузиться в значение каждого из них и как им пользоваться.
Для получения дополнительной информации о синтаксисе robots.txt и о том, как он интерпретируется Google, просмотрите документацию Google’s robots.txt.
User-Agent
Поле user-agent определяет, к какому сканеру применяются директивы (запретить, разрешить). Вы можете использовать поле агента пользователя, чтобы создать правила, применяемые к конкретным ботам/сканерам, или использовать символ подстановки, чтобы указать правила, применяемые ко всем сканерам.
Например, приведенный ниже синтаксис указывает, что любая из следующих директив применяется только к Googlebot.
агент пользователя: Googlebot
Если вы хотите создать правила, которые будут применяться ко всем сканерам, вы можете использовать символ обобщения вместо названия конкретного сканера.
агент пользователя: *
Вы можете включить несколько полей агента пользователя в свой robots.txt, чтобы предоставить специальные правила для различных сканеров или групп сканеров, например:
агент пользователя: *
#Правила здесь будут применяться ко всем сканерам
агент пользователя: Googlebot
#Правила здесь применяются только к Googlebot
агент пользователя: otherbot1
агент пользователя: otherbot2
агент пользователя: otherbot3
#Правила здесь будут применяться к otherbot1, otherbot2 и otherbot3
Запретить и разрешить
Поле запрета указывает пути, к которым сканеры не должны иметь доступа. Поле разрешения указывает пути, к которым имеют доступ назначенные сканеры.
Поскольку робот Googlebot и другие веб-сканеры будут предполагать, что они могут получить доступ к любым URL, которые не являются специально запрещенными, многие сайты остаются простыми и только указывают, к каким путям нельзя обращаться , используя поле запрета.< /p>
Например, приведенный ниже синтаксис скажет всем сканерам не обращаться к URL-адресам, соответствующим пути /do-not-enter.
агент пользователя: *
запрет: /do-not-enter
#Всем сканерам заблокировано сканирование страниц с помощью пути /do-not-enter
Если вы используете поля разрешения и запреты в файле robots.txt, обязательно прочтите раздел о приоритетности правил в документации Google.
Как правило, в случае конфликтных правил Google будет использовать более конкретное правило.
Например, в следующем случае Google не будет сканировать страницы с помощью/не вводить, поскольку правило запрета является более конкретным, чем правило разрешения.
агент пользователя: *
разрешить: /
запрет: /do-not-enter
Если ни одно из правил не является более конкретным, Google по умолчанию будет использовать менее ограничительное правило.
В приведенном ниже примере Google будет сканировать страницы с помощью/не-вводить, поскольку правило разрешения является менее ограничительным, чем правило запрета.
агент пользователя: *
позволить: /do-not-enter
запрет: /do-not-enter
Учтите, что если не указан путь для полей разрешения или запрета, правило будет проигнорировано.
агент пользователя: *
запрет:
Это существенно отличается от простого включения косого риска (/) как значения поля запрета, которое будет соответствовать корневому домену и любому URL-адресу более низкого уровня (перевод: каждая страница вашего сайта).
Если вы хотите, чтобы ваш сайт отображался в результатах поиска, убедитесь, что у вас нет следующего кода. Он заблокирует все поисковые системы от сканирования всех страниц вашего сайта.
агент пользователя: *
запрет: /
Это может показаться очевидным, но поверьте мне, я’видел это.
Пути URL

Изображение от автора, ноябрь 2024 г.
Пути URL-адресов чувствительны к регистру, поэтому обязательно проверьте, согласуется ли использование больших и нижних регистров в файле robot.txt с предполагаемым путем URL-адреса.
Специальные символы
Специальный символ — это символ, который имеет уникальную функцию или значение, а не просто представляет обычную букву или цифру. Специальные символы, которые Google поддерживает в robots.txt:
- Звездочка (*) – соответствует 0 или более экземплярам любого символа.
- Знак доллара ($) – обозначает конец URL-адреса.
Чтобы проиллюстрировать, как работают эти специальные символы, допустим, что у нас есть небольшой сайт с такими URL-адресами:
- https://www.example.com/
- https://www.example.com/search
- https://www.example.com/guides
- https://www.example.com/guides/technical
- https://www.example.com/guides/technical/robots-txt
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content
- https://www.example.com/guides/content/on-page-optimization
- https://www.example.com/guides/content/on-page-optimization.pdf
Пример сценария 1: Блокировка результатов поиска на сайте
Распространенным использованием robots.txt является блокировка внутренних результатов поиска на сайте, поскольку эти страницы обычно не ценны для результатов обычного поиска.
Для этого примера предположим, что когда пользователи осуществляют поиск на https://www.example.com/search, их запрос добавляется к URL-адресу.
Если пользователь искал “пособие с карты сайта в формате xml,” новый URL для страницы результатов поиска будет https://www.example.com/search?search-query=xml-sitemap-guide.
Если вы указываете URL-путь в robots.txt, он соответствует любым URL-адресам с этим путем, а не только точным URL-адресам. Итак, чтобы заблокировать оба приведенных выше URL, использовать символ подстановки не обязательно.
Нижеследующее правило будет соответствовать как https://www.example.com/search, так и https://www.example.com/search?search-query=xml-sitemap-guide.
агент пользователя: *
запрет: /search
#Всем сканерам заблокировано сканирование страниц с /search
Если добавить символ подстановки (*), результаты будут такими же.
агент пользователя: *
запрет: /search*
#Всем сканерам заблокировано сканирование страниц с /search
Пример сценария 2: Блокировка файлов PDF
В некоторых случаях вы можете использовать файл robots.txt для блокировки определенных типов файлов.
Представьте себе, что сайт решил создать PDF-версии каждого руководства, чтобы пользователи могли их легко распечатать. Результатом является два URL-адреса с абсолютно одинаковым содержимым, поэтому владелец сайта может захотеть заблокировать поисковым системам сканирования PDF-версий каждого руководства.
В этом случае использование символа подстановки (*) будет полезным для соответствия URL-адресам, где путь начинается с /guides/и заканчивается .pdf, но символы между ними отличаются.
агент пользователя: *
запрет: /guides/*.pdf
#Всем сканерам запрещено сканировать страницы с URL, содержащими: /guides/, 0 или более случаев любого символа и .pdf
Приведенная выше директива не позволит поисковым системам сканировать следующие URL-адреса:
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content/on-page-optimization.pdf
Пример сценария 3: Блокировать страницы категорий
Для последнего примера предположим, что сайт создал страницы категорий для технических и содержательных пособий, чтобы облегчить пользователям просмотр содержимого в будущем.
Однако, поскольку сейчас на сайте опубликовано только три руководства, эти страницы не имеют большой ценности для пользователей или поисковых систем.
Владелец сайта может временно запретить поисковым системам сканировать только страницу категории (например, https://www.example.com/guides/technical), а не пособия в категории (например, https://www.example.com/guides/technical /robots-txt).
Чтобы достичь этого, мы можем использовать “$” чтобы отметить конец URL-пути.
агент пользователя: *
запрет: /guides/technical$
запрет: /guides/content$
#Всем сканерам запрещено сканировать страницы с URL, которые заканчиваются на /guides/technical и /guides /content
Приведенный выше синтаксис будет предотвращать сканирование следующих URL:
- https://www.example.com/guides/technical
- https://www.example.com/guides/content
Позволяя поисковым системам сканировать:
- https://www.example.com/guides/technical/robots-txt
- <https://www.example.com/guides/technical/xml-sitemaps
- https://www.example.com/guides/content/on-page-optimization
Карта сайта
Поле карты сайта используется для предоставления поисковым системам ссылки на одну или более карт сайта в формате XML.
Несмотря на то, что это не обязательно, лучше всего включать XML-карты сайта в файл robots.txt, чтобы предоставить поисковым системам список приоритетных URL-адресов для сканирования.
Значением поля карты сайта должен быть абсолютный URL-адрес (например, https://www.example.com/sitemap.xml), а не относительный URL-адрес (например, /sitemap.xml). Если у вас есть несколько XML карт сайта, вы можете включить несколько полей карты сайта.
Пример robots.txt с единственной XML картой сайта:
агент пользователя: *
запрет: /do-not-enter
карта сайта: https://www.example.com/sitemap.xml
Пример robots.txt с несколькими XML-картами сайта:
агент пользователя: *
запрет: /do-not-enter
карта сайта: https://www.example.com/sitemap-1.xml
карта сайта: https://www.example.com/sitemap-2.xml
карта сайта: https://www.example.com/sitemap-3.xml
<сильный>Crawl-Delay
Как упоминалось выше, 20% сайтов также содержат поле задержки сканирования в файле robots.txt.
Поле задержки сканирования сообщает работам, как быстро они могут сканировать сайт, и обычно используется для замедления сканирования во избежание перегрузки серверов.
Значение задержки сканирования — это количество секунд, которое сканеры должны ожидать, чтобы запросить новую страницу. Приведенное ниже правило укажет указанному сканеру ждать пять секунд после каждого запроса, прежде чем запрашивать другой URL.
агент пользователя: FastCrawlingBot
задержка сканирования: 5
Другие крупные поисковые системы, такие как Bing и Yahoo, придерживаются директив по задержке сканирования для своих веб-сканеров.
<таблица style="border-collapse: collapse; width: 91,1249%; height: 91px;"> <тела>
Сайты чаще всего включают директивы задержки сканирования для всех пользовательских агентов (с использованием user-agent: *), сканеры поисковых систем, упомянутые выше, уважающие задержку сканирования, и сканеры для инструментов SEO, таких как Ahrefbot и SemrushBot .
Количество секунд, которые сканеры получали указания ждать перед запросом другого URL-адреса, колебалось от одной секунды до 20 секунд, но значения задержки сканирования в пять секунд и 10 секунд были наиболее распространенными на 60 проанализированных сайтах.
Тестирование файлов Robots.txt
Каждый раз, когда вы создаете или обновляете файл robots.txt, проверяйте директивы, синтаксис и структуру перед публикацией.
Это средство проверки и тестирования robots.txt делает это легко (спасибо, Макс Прин!).
Чтобы проверить живой файл robots.txt, просто:
- Добавьте URL, который хотите проверить.
- Выберите свой агент пользователя.
- Выберите “вживую.”
- Нажмите “test.”
Приведенный ниже пример показывает, что смартфону Googlebot разрешено сканировать проверенный URL-адрес.
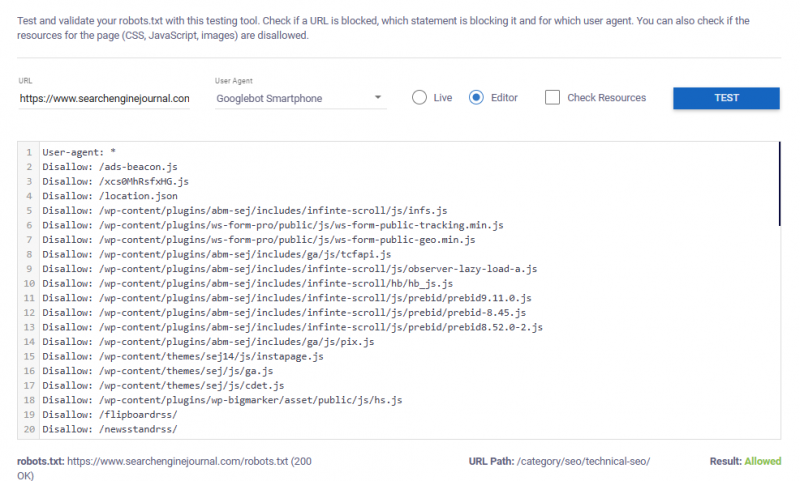
Изображение от автора, ноябрь 2024 год
Если проверенный URL-адрес заблокирован, инструмент выделит определенное правило, которое запрещает выбранному агенту пользователя сканировать его.
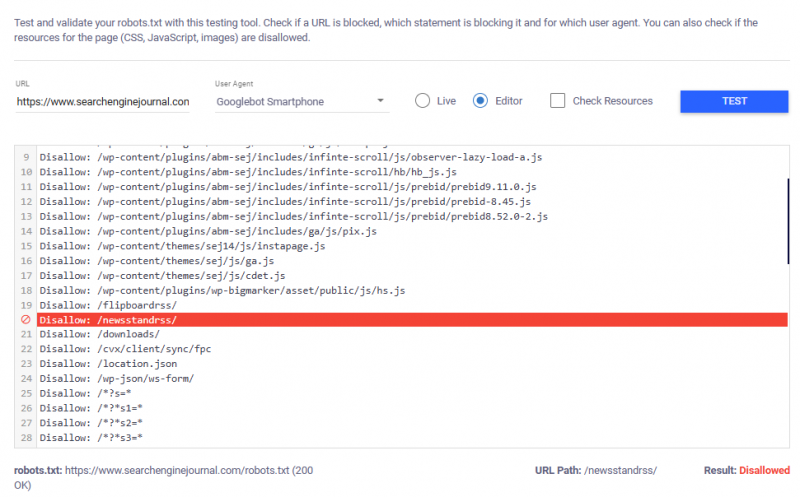
Изображение от автора, ноябрь 2024 год
Чтобы проверить новые правила перед их публикацией, перейдите к “Редактору” и вставьте свои правила в текстовое поле перед тестированием.
Общее использование файла robots.txt
Хотя то, что содержится в файле robots.txt, значительно отличается в зависимости от веб-сайта, анализ 60 файлов robots.txt выявил некоторые общие черты в том, как он используется и какой тип содержимого веб-мастера обычно блокируют поисковые системы от сканирования.
Предотвращение поисковых систем сканировать малоценное содержимое
Многие веб-сайты, особенно крупные, такие как электронная коммерция или платформы с большим содержимым, часто создают “малоценные страницы” как побочный продукт функций, предназначенных для улучшения взаимодействия с пользователем.
Например, внутренние страницы поиска и параметры фасетной навигации (фильтры и сортировка) помогают пользователям быстро и легко находить то, что они ищут.
Хотя эти функции важны для удобства использования, они могут привести к повторяющимся или малоценным URL-адресам, которые не являются ценными для поиска.
Файл robots.txt обычно используется для блокировки этих малоценных страниц от сканирования.
Распространенные типы содержимого, заблокированного с помощью robots.txt, включают:
- Параметризированные URL:URL-адреса с параметрами отслеживания, идентификаторами сеансов или другими динамическими переменными блокируются, поскольку они часто ведут к одному и тому же содержимому, что может создавать проблемы с повторяющимся содержимым и тратить бюджет на сканирование. Блокировка этих URL гарантирует, что поисковые системы индексируют только основную, чистую URL.
- Фильтры и сортировка: Блокировка фильтров и сортировка URL-адресов (например, страниц продуктов, отсортированных по цене или отфильтрованных по категориям) помогает избежать индексирования нескольких версий та же страница. Это уменьшает риск дублирования содержимого и сосредотачивает внимание поисковых систем на важнейшей версии страницы.
- Результаты внутреннего поиска:Внутренние страницы результатов поиска часто блокируются, поскольку они создают содержимое, не имеющее уникальной ценности. Если поисковый запрос пользователя будет вставлен в URL-адрес, содержимое страницы и мета-элементы, сайты могут даже рисковать, что некоторое несоответствующее, созданное пользователями содержимое будет просканировано и проиндексировано (см. пример снимка экрана в этой публикации Мэтта Тутта). Их блокировка предотвращает эту низкокачественную – и потенциально неподходящим – контент от появления в поиске.
- Профили пользователей: Страницы профилей могут быть заблокированы, чтобы защитить конфиденциальность, уменьшить сканирование малоценных страниц или обеспечить фокусировку на более важном содержимом , как страницы продукта или публикации в блогах.
- Среды тестирования, промежуточной подготовки или разработки: Среды промежуточной подготовки, разработки или тестирования часто блокируются, чтобы гарантировать, что непубличное содержимое не сканируется поисковыми системами .
- Подпапки кампании:Целевые страницы, созданные для платных медиа-кампаний, часто блокируются, если они не соответствуют более широкой поисковой аудитории (т.е. целевая страница прямой почтовой рассылки, которая предлагает пользователям ввести код активации).
- Страницы оплаты и подтверждения: Страницы проверки заблокированы, чтобы предотвратить переход пользователей на них непосредственно через поисковые системы, улучшая взаимодействие с пользователем и защищая конфиденциальную информацию во время процесса транзакции.
- Созданное пользователями и спонсируемое содержимое: Спонсорированное содержимое или созданное пользователями содержимое, созданное с помощью обзоров, вопросов, комментариев и т.п., часто блокируется от сканирования поисковыми системами.
- Медиафайлы (изображение, видео):Иногда блокируется сканирование мультимедиа, чтобы сохранить пропускную способность и уменьшить видимость частного содержимого при поиске двигателей. Это гарантирует, что только соответствующие веб-страницы, а не отдельные файлы, будут отображаться в результатах поиска.
- API:API часто блокируют, чтобы предотвратить их сканирование или индексирование, поскольку они предназначены для межмашинной связи, а не для результатов поиска конечного пользователя. Блокировка API защищает их использование и уменьшает ненужную нагрузку на сервер от ботов, которые пытаются получить к ним доступ.
<сильный>Блокировка “Плохо” Боты
Плохие боты — это веб-сканеры, участвующие в нежелательных или вредоносных действиях, таких как копирование содержимого и, в экстремальных случаях, поиск уязвимостей для похищения конфиденциальной информации.
Другие боты без каких-либо злых намерений могут считаться “плохими” если они заполняют веб-сайты слишком большим количеством запросов, перегружая серверы.
Кроме того, веб-мастера могут просто не захотеть, чтобы определенные сканеры получали доступ к их сайту, потому что они ничего не получат от этого.
Например, вы можете заблокировать Baidu, если вы не обслуживаете клиентов в Китае и не хотите, чтобы запросы от Baidu повлияли на ваш сервер.
Хотя некоторые из этих “плохих” боты могут пренебрегать инструкциями, изложенными в файле robots.txt, веб-сайты все еще обычно включают правила их запрета.
Из 60 проанализированных файлов robots.txt 100% запретили по крайней мере одному агенту пользователя доступ ко всему содержимому на сайте (через запрет: /).
Блокировка сканеров AI
Среди проанализированных сайтов наиболее заблокированным сканером был GPTBot: 23% сайтов блокируют GPTBot сканирование любого содержимого на сайте.
Причины блокировки веб-сканеров AI могут быть разными – от беспокойства относительно контроля данных и конфиденциальности до простого нежелания использовать ваши данные в учебных моделях ИИ без компенсации.
Решение о том, блокировать или нет ботов ИИ с помощью robots.txt, следует оценивать в каждом конкретном случае.
Если вы не хотите, чтобы содержимое вашего сайта использовалось для обучения искусственному интеллекту, но также хотите максимизировать видимость, вам повезло. OpenAI прозрачно использует GPTBot и другие веб-сканеры.
Как минимум, сайты должны рассмотреть возможность разрешения OAI-SearchBot, которое используется для показа и ссылок на веб-сайты в SearchGPT – ChatGPT’s недавно запустил функцию поиска в реальном времени.
Блокировка OAI-SearchBot гораздо реже, чем блокировка GPTBot, только 2,9% из 1000 самых популярных сайтов блокируют сканер, ориентированный на SearchGPT.
Креативность
Кроме того, что файл robots.txt является важным инструментом контроля доступа веб-сканеров к вашему сайту, он также может являться возможностью для сайтов продемонстрировать свою “креативность” стороне.
Просматривая файлы из более 60 сайтов, я также наткнулся на несколько замечательных сюрпризов, таких как веселые иллюстрации, скрытые в комментариях к файлам robots.txt Marriott и Cloudflare&rsquo.

Снимок экрана marriot.com/robots.txt, ноябрь 2024 г.
Снимок экрана cloudflare.com/robots.txt, ноябрь 2024 г.
Несколько компаний даже превращают эти файлы в уникальные инструменты найма.
<цитата>
“Если вы обнюхиваете этот файл, и вы’не робот, мы’стремимся встретиться с интересными людьми, такими как вы…~60>
Выполнить – не не ползать &nd;; подать заявку на присоединение к элитной команде SEO TripAdvisor’
Если вы&ищете новую карьерную возможность, вы можете рассмотреть возможность просмотра файлов robots.txt в дополнение к LinkedIn.
Как проверить файл Robots.txt
Аудит вашего файла Robots.txt является важной частью большинства технических аудитов SEO.
Проведение тщательного аудита robots.txt гарантирует, что ваш файл оптимизирован для улучшения видимости сайта без непреднамеренного ограничения важных страниц.
Чтобы проверить ваш файл Robots.txt:
- Сканируйте сайт с помощью желаемого сканера.
- Фильтр сканирования для любых страниц, помеченных как “заблокированных robots.txt.” ;заблокирован robots.txt.”
- Просмотрите список URL, заблокированных файлом robots.txt, чтобы определить, стоит ли стоит ихблокировать. Обратитесь к приведенному выше списку распространенных типов содержимого, заблокированному robots.txt, чтобы помочь вам определить, должны ли заблокированные URL быть доступными для поисковых систем.
- Откройте свой файл robots.txt и проведите дополнительные проверки, чтобы убедиться, что ваш файл robots.txt соответствует лучшим практикам SEO (и избегает распространенных ошибок), описанным ниже.
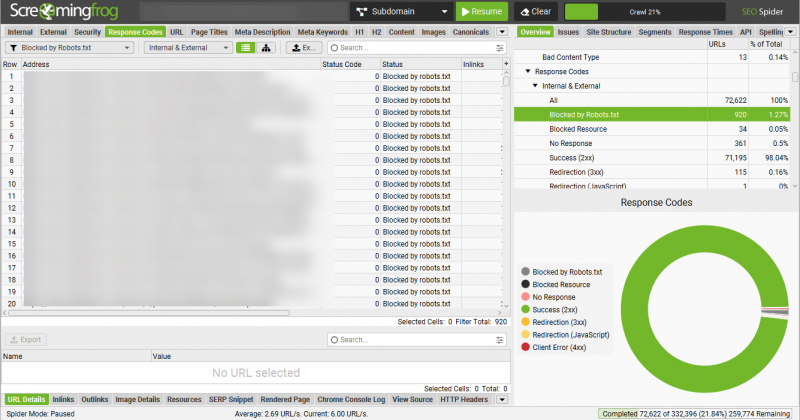
Изображение от автора, ноябрь 2024 г.
Robots.txt Лучшие методы (и подводные камни, которых следует избегать)
Файл robots.txt является мощным инструментом при эффективном использовании, но есть некоторые типичные подводные камни, которых следует избегать, если вы не хотите ненамеренно нанести вред сайту.
Приведенные ниже практические советы помогут вам настроиться на успех и избежать непреднамеренной блокировки поисковыми системами сканирования важного содержимого:
- Создайте файл robots.txt для каждого субдомена.Каждый субдомен на вашем сайте (например, blog.yoursite.com, shop.yoursite.com ) должен иметь собственный файл robots.txt для управления правилами сканирования, характерными для этого субдомена. Поисковые системы рассматривают субдомены как отдельные сайты, поэтому уникальный файл обеспечивает надлежащий контроль над тем, какое содержимое сканируется или индексируется.
- Не блокируйте важные страницы на сайте.Убедитесь, что приоритетное содержимое, например страницы продуктов и услуг, контактная информация и содержимое блога доступны для поисковых систем. Кроме того, убедитесь, что заблокированные страницы не препятствуют поисковым системам получить доступ к ссылкам на содержимое, которое вы хотите сканировать и индексировать.
- Не блокируйте важные ресурсы. Блокировка JavaScript (JS), CSS или файлов изображений может помешать поисковым системам отобразить ваш сайт правильно. Убедитесь, что важные ресурсы, необходимые для правильного отображения сайта, не запрещены.
- Включить ссылку на карту сайта.Всегда включайте ссылку на вашу карту сайта в файл robots.txt. Это облегчает поисковым системам поиск и более эффективно сканирование ваших важных страниц.
- Не rsquo;не разрешайте только определенным работам доступ к вашему сайту.Если вы запрещаете всем работам сканировать ваш сайт, кроме поиска таких двигателей, как Googlebot и Bingbot, вы можете ненамеренно заблокировать ботов, которые могут принести пользу вашему сайту. Примеры ботов включают:
- FacebookExtenalHit – используется для получения протокола открытого графа.
- GooglebotNews – используется для вкладки Новости в Поиске Google и в программе Новости Google.
- AdsBot-Google – используется для проверки качества рекламы на веб-странице.
- Не’не блокируйте URL-адреса, которые вы хотите удалить из индекса.Блокировка URL-адреса в файле robots.txt только предотвращает его сканирование поисковиками, а не индексирование, если URL-адрес уже известен. Чтобы удалить страницы из индекса, используйте другие методы, например “noindex” инструменты удаления тегов или URL, гарантируя, что они правильно исключены из результатов поиска.
- Не блокируйте Google и другие основные поисковые системы от сканирования всего вашего сайта. Просто не’не делайте этого.
<сильный>TL;DR
- Файл robots.txt указывает сканерам поисковой системы, к которым разделам веб-сайта получить доступ или избегать, оптимизируя эффективность сканирования, сосредотачиваясь на страницах высокой ценности.
- Ключевые поля включают “Агент пользователя” чтобы указать целевой сканер, “Disallow” для зон ограниченного доступа и “Карта сайта” для приоритетных страниц. Файл также может содержать такие директивы как “Разрешить” и “Задержка сканирования.”
- Веб-сайты обычно используют robots.txt для блокирования внутренних результатов поиска, малоценных страниц (например, фильтры, параметры сортировки) или конфиденциальных областей, таких как страницы оформления заказа и API.
- Возрастает количество веб-сайтов, блокирующих сканеры ИИ, такие как GPTBot, хотя это может быть не лучшей стратегией для сайтов, стремящихся получить трафик из дополнительных источников. Чтобы максимально увеличить видимость сайта, позвольте по крайней мере OAI-SearchBot.
- Чтобы настроить свой сайт на успех, убедитесь, что каждый субдомен имеет собственный файл robots.txt, проверьте директивы перед публикацией, добавьте XML-декларацию карты сайта и избегайте случайной блокировки ключевого содержимого.