
<стр.>Понимание вызовов Generative AI в эпоху открытого Интернета. Как технология GenAI может формировать публичный дискурс и качество информации.
Много было сказано о чрезвычайных возможностях Generative AI (GenAI), и некоторые из нас также были чрезвычайно громкими относительно рисков, связанных с использованием этой трансформационной технологии.
Развитие GenAI создает значительные проблемы для качества информации, публичного дискурса и общего открытого Интернета. Мощность GenAI относительно предсказания и персонализации содержимого может быть легко использована для манипулирования тем, что мы видим и с чем взаимодействуем. /h2>
Генеративные поисковые системы искусственного интеллекта создают общий шум, и вместо того, чтобы помогать людям находить правду и формировать беспристрастные мысли, они стремятся (по крайней мере, в их текущей реализации) способствовать эффективности над точностью, как подчеркивает недавнее исследование Jigsaw, подразделения Google.
Несмотря на ажиотаж вокруг вечеринок SEO-аллигаторов и контент-гоблинов, наше поколение маркетологов и профессионалов SEO потратило годы на создание более положительной веб-среды.
Мы’переместили фокус маркетинга по манипулированию аудиторией на расширение ее возможностей знаниями, в конечном счете помогая заинтересованным сторонам принимать обоснованные решения.
Создание онтологии для поисковой оптимизации – это усилие под руководством сообщества, идеально согласующееся с нашей текущей миссией по формированию, совершенствованию и предоставлению указаний, которые действительно способствуют взаимодействию между человеком и GenAI, сохраняя при этом создателей содержимого и Интернет как общий ресурс знаний и процветания.
Краткий обзор традиционных практик SEO и их эволюция
Традиционная практика SEO в начале 2010-х сосредотачивалась на оптимизации ключевых слов. Это включало такие тактики, как набор ключевых слов, схемы ссылок и создание низкокачественного контента, предназначенного в основном для поисковых систем.
С тех пор поисковая оптимизация изменилась на подход, ориентированный на пользователя. Обновление Hummingbird (2013) ознаменовало переход Google&rsquo к семантическому поиску, целью которого является понимание контекста и цели поисковых запросов, а не только ключевых слов.
Эта эволюция заставила профессионалов SEO сосредоточиться больше на тематических кластерах и сущностях, чем на отдельных ключевых словах, улучшая способность содержимого отвечать на многочисленные запросы пользователей.
Сути — это отдельные элементы, такие как люди, места или вещи, которые поисковые системы распознают и понимают как отдельные понятия.
Создавая содержимое, которое четко определяет и связывает эти сущности, организации могут улучшить свою видимость на разных платформах, а не только в традиционном веб-поиске.
Этот подход связан с более широкой концепцией оптимизации поисковых систем на основе сущности, которая гарантирует, что сущность, связанная с бизнесом, четко определена в Интернете.
От статического содержимого к семантическим данным
Возвращаясь к сегодняшнему дню, статическое содержимое, имеющее целью получить высокий рейтинг в поисковых системах, постоянно трансформируется и обогащается семантическими данными.
Это предполагает структурирование информации так, чтобы она была понятна не только людям, но и машинам.
Этот переход имеет решающее значение для работы Графов знаний и ответов, созданных искусственным интеллектом, таких как предлагаемые AIO Google или Bing Copilot, которые предоставляют пользователям прямые ответы и ссылки на соответствующие веб-сайты.
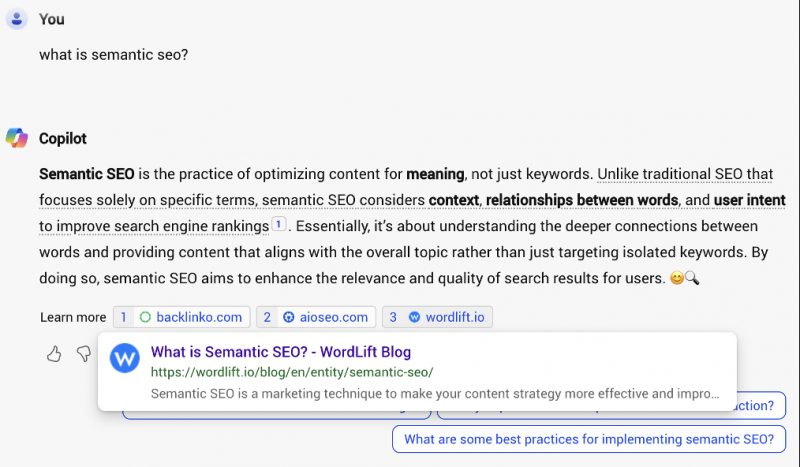
Снимок экрана с Bing Copilot, август 2024 г.
По мере того, как мы двигаемся вперед, растет важность согласования содержимого с семантическим поиском и пониманием сущности.
поисковыми системами, таким образом улучшая видимость во многих цифровых поверхностях, таких как голосовой и визуальный поиск.
Использование искусственного интеллекта и автоматизации в этих процессах растет, что обеспечивает более динамичное взаимодействие с контентом и персонализированный опыт пользователя.
Нравится нам это или нет, ИИ поможет нам быстрее сравнивать варианты, выполнять глубокий поиск без усилий и осуществлять транзакции без перехода через веб-сайт .
Автоматизация и ИИ в SEO
Будущее SEO многообещающее. Ожидается, что объем рынка услуг SEO вырастет с 75,13 миллиарда долларов США в 2023 году до 88,91 миллиарда долларов США в 2024 году. потрясающий CAGR в 18,3% (по данным The Business Research Company) – поскольку он адаптируется для включения надежного ИИ и семантических технологий.
Эти инновации способствуют созданию более динамичной и чувствительной веб-среды, которая умело удовлетворяет потребности и поведение пользователей.
Однако этот путь не обошелся без труда, особенно на крупных предприятиях. Внедрение решений искусственного интеллекта, которые являются понятными и стратегически согласованными с целями организации, было сложной задачей. 60~/p>
Это отличает организацию от конкурентов, использующих подобные языковые модели или шаблоны разработки, например разговорных агентов или копилотов поколения с дополненным поиском, и улучшает его уникальное ценностное предложение.
Введение в SEOнтологию и ее значение в современном цифровом ландшафте
Что такое онтология для SEO с точки зрения непрофессионала?
Представьте себе онтологию как гигантскую инструкцию для описания конкретных концепций. В мире SEO мы имеем дело с большим количеством жаргонов, верно? Актуальность, обратные ссылки, E-E-A-T, структурированные данные – это может запутать!
Онтология для SEO — это огромное соглашение о том, что означают все эти термины. Это как общий словарь, но еще лучше. Этот словарь не просто определяет каждое слово. Это также показывает, как все они сочетаются и работают вместе. Итак, “запросы” может быть связано с “целью поиска” и “веб-страницы,” объясняя, как все они играют роль в успешной стратегии SEO.
Представьте себе это как распутывание большого узла практик и терминов SEO и превращение их в четкую организованную карту – вот сила онтологии!
Хотя Schema.org является фантастическим примером связанного словаря, он сосредоточен на определении конкретных атрибутов веб-страницы, таких как тип содержимого или автор. Он отлично помогает поисковым системам понять наше содержимое. Но как насчет того, как мы создаем ссылки между веб-страницами?
Что касается запроса, по которому чаще всего ищут веб-страницу? Это важные элементы в нашей повседневной работе, и онтология также может быть общей структурой для них. Думайте об этом как об игровой площадке, где каждый может внести свой вклад в GitHub, подобно тому, как развивается словарь Schema.org.
Идея онтологии для SEO состоит в том, чтобы дополнить Schema.org расширением, подобным тому, что сделал GS1, создав свой словарь. Итак, это база данных? Платформа для сотрудничества или что? Это все эти вещи вместе. Онтология SEO работает как общая база знаний.
Он действует как центральный центр, где каждый может внести свой опыт в определение ключевых концепций SEO и их взаимосвязи. Устанавливая общее понимание этих концепций, сообщество SEO играет решающую роль в формировании будущего опыта искусственного интеллекта, ориентированного на человека.
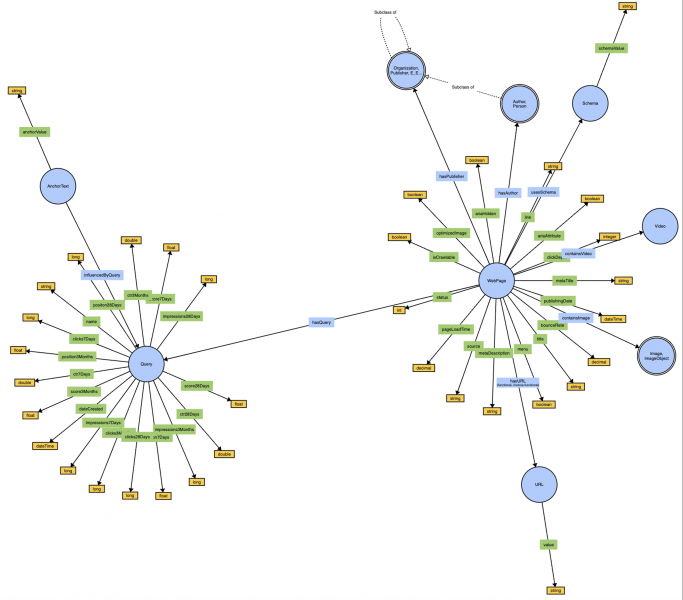
Снимок экрана с WebVowl, август 2024 SEOntology &nd; снимок (см. интерактивную визуализацию здесь).
Проблема совместимости данных в индустрии SEO
Начнем с малого и рассмотрим преимущества общей онтологии на практическом примере (вот слайд из презентации Эмилии Георгевской на нынешнем ZagrebSEOSummit)

Изображение от Emilija Gjorgjevska’s, ZagrebSEOSummit, август 2024 г.
Представьте, что коллега Валентина использует расширение Chrome для экспорта данных из Google Search Console (GSC) в Google Таблице. Данные содержат такие столбцы, как “ID,” “Запрос,” и “Впечатление” (как показано слева). Но Валентина сотрудничает с Яном, который создает бизнес-уровень, используя те же данные GSC. Вот проблема: Ян использует другое соглашение об именовании (“UID,” “Имя,” “Impressionen,” и “ Клики&rdquo ;).
Теперь расширьте этот сценарий. Представьте себе, что вы работаете с n разными партнерами по обработке данных, инструментами и членами команды, использующими разные языки. Усилия постоянно переводить и согласовывать эти различные договоренности о наименовании становятся основным препятствием для эффективного сотрудничества данных.
Значительная ценность теряется, просто пытаясь вынудить все работать вместе. Вот где на помощь приходит онтология SEO. Это общий язык, который дает общее название для одной концепции в различных инструментах, партнерах и языках.
Устраняя потребность в постоянном переводе и согласовании, онтология SEO оптимизирует сотрудничество с данными и раскрывает истинную ценность ваших данных.
Генеза сеонтологии
В прошлом году мы стали свидетелями распространения агентов искусственного интеллекта и широкого внедрения Retrieval Augmented Generation (RAG) во всех его разнообразных формах (модульная, графическая RAG и т.д.).< /p>
RAG представляет собой важный шаг вперед в технологии AI, устраняя ключевое ограничение традиционных больших языковых моделей (LLM), предоставляя им доступ к внешним знаниям.
Традиционно LLM – это библиотеки с одной книгой – ограничены данными об обучении. RAG открывает широкую сеть ресурсов, позволяя LLM предоставлять более исчерпывающие и точные ответы.
RAG улучшают фактическую точность и понимание контекста, потенциально уменьшая пристрастность. Несмотря на перспективу, RAG сталкивается с проблемами безопасности данных, точности, масштабируемости и интеграции, особенно в корпоративном секторе.
Для успешного внедрения RAG нужны высококачественные структурированные данные, к которым можно легко получить доступ и масштабировать их.
Мы были одними из первых, кто экспериментировал с агентами искусственного интеллекта и RAG на базе Knowledge Graph в контексте создания содержимого и автоматизации поисковых систем.
Снимок экрана от Agent WordLift, август 2023 г.
Графы знаний (KG) действительно набирают обороты в разработке RAG
Подходы RAG на базе KG, такие как предложенный LlamaIndex в сочетании с WordLift, решают это, создавая график знаний из данных веб-сайта и используя его вместе с LLM для повышения точности ответов, особенно на сложные вопросы.

Изображение от автора, август 2024 г.
Мы тестировали рабочие процессы с клиентами в различных отраслях в течение более года.
От исследования ключевых слов для больших редакционных групп до генерирования вопросов и ответов для веб-сайтов электронной коммерции, от распределения содержимого до составления плана информационного бюллетеня или обновления существующих статей, мы тестировали разные стратегии и научились кое-чему попутно :
1. RAG превышен
Это просто один из многих шаблонов развития, которые достигают цели большей сложности. RAG (или Graph RAG) призван помочь вам сэкономить время на поиске ответа. Это отлично, но не решает никаких маркетинговых задач, которые команда должна выполнять каждый день. Вам нужно сосредоточиться на данных и модели данных.
Хотя есть хорошие RAG и плохие RAG, ключевую дифференциацию часто представляют “R” Часть уравнения: Поиск. Прежде всего, поиск отличает модную демонстрацию от реальной программы, а по хорошему RAG всегда есть хорошие данные. Однако данные — это не любой тип данных (или данных графика).
Это построено вокруг согласованной модели данных, которая имеет смысл для вашего случая использования. Если вы создаете поисковую систему для вин, вам нужно получить лучший набор данных и моделировать данные вокруг функций, на которые пользователь будет полагаться, ища информацию.
Итак, данные важны, но модель данных еще важнее. Если вы создаете агента с искусственным интеллектом, который должен делать что-то в вашей маркетинговой экосистеме, вы должны соответствующим образом моделировать данные. Вы хотите представить суть веб-страниц и ресурсов содержимого.
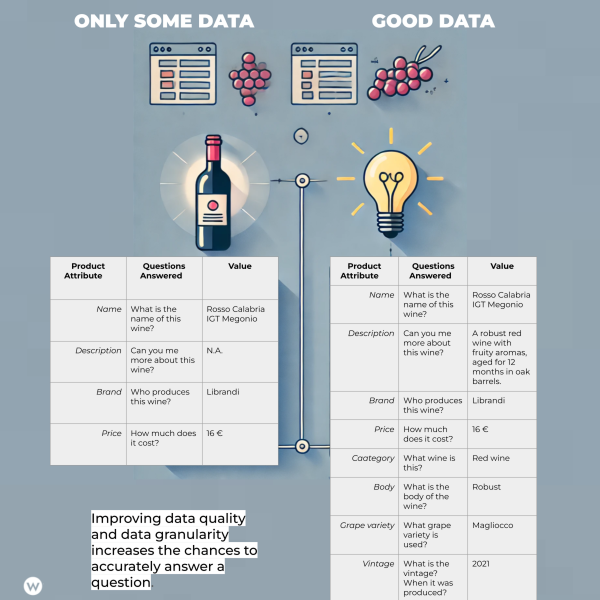
Изображение от автора, август 2024 г.
2. Не все отлично подсказывают
Выложить задачу в письменной форме трудно. Разработка подсказок полной скоростью движется к автоматизации (вот моя статья о переходе от подсказок к программированию подсказок для SEO), поскольку лишь несколько экспертов могут написать подсказку, которая приведет нас к ожидаемому результату.
Это создает несколько проблем для разработки пользовательского опыта автономных агентов. Джейкон Нильсен очень активно говорил о негативном влиянии подсказок на удобство использования программ ИИ:
“Одним из основных недостатков удобства использования является то, что пользователи должны быть очень четкими, чтобы написать необходимый прозаический текст для подсказок.”
Даже в богатых западных странах статистика, предоставленная Nielsen, говорит нам, что <сильный>только 10% населения может полностью использовать ИИ!~~~~~~~~~~~~~~~~~~ <стол> <тела>
3. Вы должны строить рабочие процессы, чтобы управлять пользователем
Добытый урок состоит в том, что мы должны создать подробные стандартные рабочие процедуры (SOP) и письменные протоколы, описывающие шаги и процессы для обеспечения согласованности, качество и эффективность в выполнении конкретных задач оптимизации.
Мы можем увидеть эмпирические доказательства роста числа быстрых библиотек, подобных той, что предлагается пользователям моделей Anthropic, или невероятного успеха таких проектов, как AIPRM.
На самом деле мы узнали, что бизнес ценность создает ряд шагов ci, которые помогают пользователю перевести контекст, в котором он/она перемещается, в последовательное определение задачи.
Мы можем начать представлять маркетинговые задачи, например проведение исследования ключевых слов, как стандартную операционную процедуру, которая может направлять пользователя через несколько шагов (вот как мы планируем СОП для выявления ключевых слов с помощью агента WordLift)
<сильный>4. Большой переход к UX вовремя
В традиционном дизайне UX информация заранее определена и может быть организована в иерархии, таксономии и предварительно определены шаблоны пользовательского интерфейса. Когда ИИ становится интерфейсом к сложному миру информации, мы наблюдаем изменение парадигмы.
Топологии пользовательского интерфейса имеют тенденцию исчезать, а взаимодействие между людьми и ИИ остается преимущественно диалоговым. Вспомогательные рабочие процессы «точно вовремя» могут помочь пользователю контекстуализировать и улучшить рабочий процесс.
- Вам нужно думать с точки зрения создания стоимости бизнеса, сосредоточиться на интерактивном путешествии пользователя’ , а также способствовать взаимодействию, создавая UX на лету. Таксономии остаются стратегическим активом, но они действуют за кулисами, поскольку пользователь телепортируется от одной задачи к другой, как недавно блестяще описал Яннис Паниарас из Microsoft.
Сотрудничество с Advertools для совместимости данных
Так же мы сотрудничали с гениальным Элиасом Даббасом, создателем Advertools — любимая библиотека Python среди маркетологов – автоматизировать широкий спектр маркетинговых задач.
Наши совместные усилия направлены на улучшение совместимости данных, обеспечивая безупречную интеграцию и обмен данными между различными платформами и инструментами.
В первом Блокноте, доступном в репозитории SEOntology GitHub, Элиас демонстрирует, как можно легко создавать атрибуты для класса WebPage, включая заголовок, метаопись, изображения и ссылки. Эта основа позволяет легко моделировать сложные элементы, например стратегии внутреннего связывания. Смотрите здесь структуру:
- Внутренние_ссылки
-
- anchorTextContent
- NoFollow
- Ссылка
Мы также можем добавить метку, если страница уже использует разметку схемы:
- использует схему
Оформление того, что мы узнали из анализа утечки поисковых документов Google
Хотя мы хотим быть чрезвычайно осознанными, выводя тактику или мелкие схемы из массовой утечки Google и хорошо осознавая, что Google быстро предотвратит любое потенциальное злоупотребление такой информацией, существует большой уровень информации, исходя из того, что мы узнали, может быть использован для улучшения того, как мы представляем веб-контент и упорядочиваем маркетинговые данные.
Несмотря на эти ограничения, утечка предлагает ценную информацию об улучшении представления веб-содержимого и организации маркетинговых данных. Чтобы демократизировать доступ к этой информации, я разработал инструмент Google Leak Reporting, предназначенный для того, чтобы сделать эту информацию легкодоступной для SEO-профессионалов и цифровых маркетологов.
Например, понимание системы классификации Google’и ее сегментации веб-сайтов по разным таксономиям было особенно поучительным. Эти таксономии – например ‘verticals4’, ‘geo’, ‘products_services’ – играют решающую роль в рейтинге и релевантности поиска, каждый из которых имеет уникальные атрибуты, влияющие на то, как веб-сайты и содержимое воспринимаются и ранжируются в результатах поиска.
Используя SEOntology, мы можем применить некоторые из этих атрибутов для улучшения представления веб-сайта.
А теперь остановитесь на секунду и представьте, как превращаете сложные данные SEO, которыми вы управляете ежедневно с помощью таких инструментов как Moz, Ahrefs, Screaming Frog, Semrush и многих других, в интерактивный график. Теперь представьте автономного агента искусственного интеллекта, такого как Agent WordLift, рядом с вами.
Этот агент использует нейро-символический искусственный интеллект, передовой подход, сочетающий в себе возможности нейронного обучения с символическим мышлением, чтобы автоматизировать такие задачи SEO, как создание и обновление внутренних ссылок. Это упрощает ваш рабочий процесс и обеспечивает уровень точности и эффективности, ранее недостижимый.
SEOntology служит основой для этого видения, предоставляя структурированную структуру, которая обеспечивает бесперебойный обмен и повторное использование данных SEO на разных платформах и инструментах. Благодаря стандартизации того, как данные SEO представлены и взаимосвязаны, SEOntology гарантирует, что ценные сведения, полученные с одного инструмента могут быть легко применены и использованы другими. К примеру, данные об эффективности ключевых слов из SEMrush могли бы стать основой для стратегий оптимизации содержимого в WordLift, и все это в единой, совместимой среде. Это не только максимизирует полезность существующих данных, но и ускоряет процессы автоматизации и оптимизации, которые являются ключевыми для эффективного маркетинга.
Внедрение ноу-хау SEO в агентов AI
Пока мы разрабатываем новый агентский подход к SEO и цифровому маркетингу, SEOntology служит нашим предметно-ориентированным языком (DSL) для кодирования навыков SEO в агентах ИИ. Давайте посмотрим на практический пример того, как это работает.
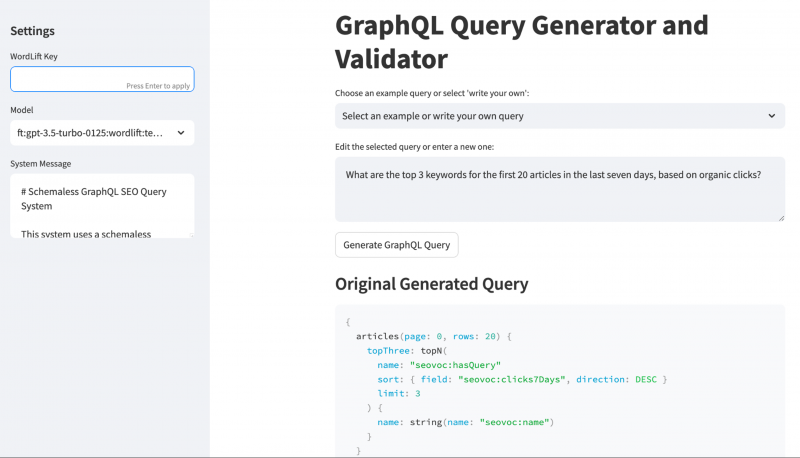
Снимок экрана с WordLift, август 2024 г.
Мы разработали систему, которая извещает агентов искусственного интеллекта о производительности обычного поиска веб-сайта, обеспечивая новый вид взаимодействия между профессионалами по поисковой оптимизации и искусственным интеллектом. Вот как работает прототип:
Компоненты системы
- Knowledge Graph: сохраняет данные Google Search Console (GSC), закодированные с помощью SEOntology.
- LLM: Перевод запросов на естественный язык на GraphQL и анализ данных.
- AI Agent: Предоставляет информацию на основе проанализированных данных.
<сильный>Взаимодействие человек-агент
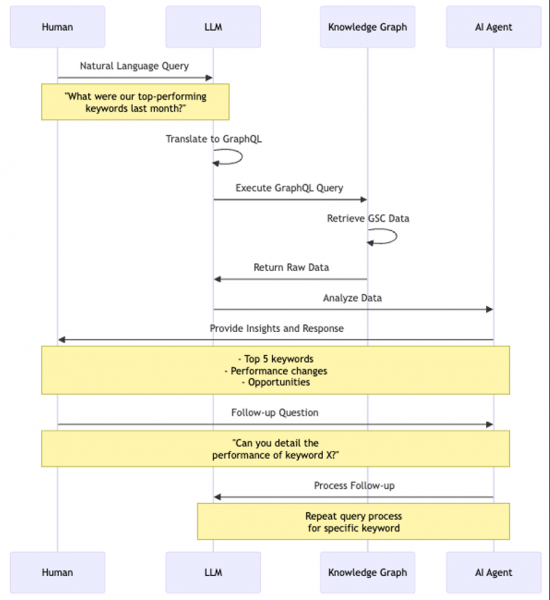
Изображение от автора, август 2024 г.
Диаграмма иллюстрирует поток типичного взаимодействия. Вот что делает этот подход мощным:
- Интерфейс естественного языка: SEO-профессионалы могут задавать вопросы простым языком, не строя сложных запросов.
- Контекстуальное понимание: LLM понимает концепции SEO, позволяя более тонкие запросы и ответы.
- Обстоятельный анализ: агент AI не просто получает данные; он предоставляет практическую информацию, например:
- Определение наиболее эффективных ключевых слов.
- Освещение значительных изменений производительности.
- Предложение возможностей оптимизации.
- Интерактивное исследование: пользователи могут задавать дополнительные вопросы, что позволяет динамически исследовать производительность SEO.
Кодируя знания о SEO с помощью SEOntology и интегрируя данные о производительности, мы создаем агентов искусственного интеллекта, которые могут оказывать контекстно-взвешивающую и подробную помощь в задачах SEO. Этот подход устраняет разрыв между необработанными данными и практическими выводами, делая расширенный анализ SEO более доступным для профессионалов всех уровней.
Этот пример иллюстрирует, как такая онтология, как SEOntology, может дать нам возможность создавать агентские инструменты SEO, автоматизирующие сложные задачи, сохраняя человеческий надзор и обеспечивая качественные результаты. Это взгляд на будущее SEO, где искусственный интеллект увеличивает человеческий опыт, а не заменяет его.
Human-In-The-Loop (HTIL) и общий обмен знаниями
Скажем четко: хотя искусственный интеллект совершает революцию в поисковой системе и поисковой системе, люди являются сердцем нашей отрасли. Поскольку мы глубже погружаемся в мир SEOntology и рабочих процессов с помощью искусственного интеллекта, очень важно понимать, что Human-in-the-Loop (HITL) — это не просто модное приложение— rsquo;это основа всего, что мы’строим.
Суть создания SEOntology состоит в том, чтобы передать наш коллективный опыт в поисковой системе на машины, гарантируя, что мы, как люди, будем оставаться твердо сидеть за рулем’. Дело не в том, чтобы передать ключи ИИ; речь идет о научить его быть лучшим вторым пилотом в нашем путешествии к SEO.
ШИ под руководством человека: незаменимый человеческий элемент
SEOntology — это больше, чем техническая структура – это катализатор для совместного обмена знаниями, подчеркивающий человеческий потенциал в SEO. Наши обязательства выходят за рамки кода и алгоритмов, а также развивают навыки и расширяют возможности маркетологов нового поколения и профессионалов по оптимизации поисковых систем.
Почему? Потому что подлинная сила искусственного интеллекта в оптимизации поисковых систем раскрыта благодаря человеческому пониманию, разнообразным взглядам и опыту реального мира. После многих лет работы с рабочими процессами искусственного интеллекта я понял, что агентивное SEO в основном ориентировано на человека. Мы’не заменяем экспертизу; мы усиливаем его.
Мы обеспечиваем более эффективные и надежные результаты, сочетая передовые технологии с человеческим творчеством, интуицией и нравственным суждением. Такой подход создает доверие клиентов в нашей отрасли и в Интернете.
Вот где люди остаются незаменимыми:
- Понимание бизнес-потребностей: искусственный интеллект может вычислять цифры, но не может’ заменить подробное понимание бизнес-целей, которое предлагают опытные профессионалы SEO. Нам нужны эксперты, которые смогут превратить цели клиента в действенные стратегии SEO.
- Определение клиентских ограничений: Каждый бизнес уникален со своими ограничениями и возможностями. Чтобы преодолеть эти ограничения и разработать индивидуальные подходы к оптимизации поисковых систем, работающих в пределах реальных параметров, нужно человеческое понимание.
- Разработка передовых алгоритмов: Алгоритмы, обеспечивающие работу наших инструментов ИИ, не возникают из воздуха. Нам нужны блестящие умы, чтобы разрабатывать самые современные алгоритмы, учиться на человеческом вкладе и постоянно совершенствоваться.
- Надежные инженерные системы: За каждым бесперебойным инструментом искусственного интеллекта стоит команда разработчиков программного обеспечения, гарантирующих, что наши системы являются быстрыми, безопасными и надежными . Благодаря человеческому опыту наши помощники ИИ работают как хорошо смазанные машины.
- Страсть к лучшему Интернету: В основе SEO лежит стремление сделать Интернет лучшим местом Нам нужны люди, которые разделяют видение Тима Бернерса&Ли&Люди, которые увлечены разработкой сети данных и улучшением цифровой экосистемы для всех.
- Объединение и устойчивость сообщества: нам нужно объединиться, чтобы проанализировать поведение поисковых гигантов и разработать устойчивые стратегии. Речь идет об инновационном решении наших проблем как отдельных лиц, так и коллектива. Это то, что мне всегда нравилось в индустрии SEO!
Расширение охвата SEOntology
Продолжая развивать SEOntology, мы’не работаем изолированно. В то же время мы строим и расширяем существующие стандарты, в частности Schema.org, и следуем успешной модели веб-словаря GS1.
SEOntology как расширение Schema.org
Schema.org стал стандартом де-факто для структурированных данных в сети, предоставляя общий словарный запас, который веб-мастера могут использовать для разметки своих страниц.
Однако, несмотря на то, что Schema.org охватывает широкий спектр концепций, он не погружается глубоко в элементы SEO. Здесь на помощь приходит SEOntology.
Расширение Schema.org, как и SEOntology, по сути является дополнительным словарем, который добавляет новые типы, свойства и связи к основному словарю Schema.org.
Это позволяет нам поддерживать совместимость с существующими реализациями Schema.org, одновременно вводя концепции, связанные с SEO, которые не рассматриваются в основном словаре.
Изучение веб-словаря GS1
Веб-словарь GS1 предлагает отличную модель для создания успешного расширения, безупречно взаимодействующего со Schema.org. GS1, глобальная организация, разрабатывающая и поддерживающая стандарты цепи поставок, создала свой веб-словарь, чтобы расширить Schema.org для случаев электронной коммерции и использования информации о продукте.
Веб-словарь GS1 демонстрирует, даже недавно, как отраслевые расширения могут влиять и взаимодействовать с разметкой схемы:
- Влияние в реальном мире: свойство https://schema.org/Certification, которое теперь официально принято Google, происходит от GS1&rsquo ; s https://www.gs1.org/voc/CertificationDetails. Это демонстрирует, как расширения могут стимулировать развитие Schema.org и возможностей поисковой системы.
Мы хотим придерживаться подобного подхода, чтобы расширить Schema.org и стать стандартным словарем для программ, связанных с SEO, потенциально повлияв на будущие возможности поисковых систем, рабочие процессы, управляемые ИИ, и практики SEO.
Подобно тому, как GS1 определил свое пространство имен (gs1:) во время ссылок на термины схемы, мы определили наше пространство имен (seovoc:) и, когда это возможно, интегрируем классы в иерархию Schema.org.
Будущее SEOntology
SEOntology — это больше, чем просто теоретическая основа; это практический инструмент, созданный для расширения возможностей профессионалов по поисковой оптимизации и производителей инструментов в экосистеме, все больше управляется ИИ.
Вот как вы можете привлекать и извлекать пользу от SEOntology.
Если вы разрабатываете инструменты SEO:
- Интерсовместимость данных: Внедрение SEOntology для экспорта и импорта данных в стандартизированном формате. Это гарантирует, что ваши инструменты могут легко взаимодействовать с другими системами, совместимыми с SEOntology.
- Данные, готовые к искусственному интеллекту: структурируя данные в соответствии с SEOntology, вы делаете их более доступными для автоматизации и анализы.
Если вы профессионал SEO:
- Внести вклад в развитие: Так же, как из Schema.org, вы можете внести вклад в развитие SEOntology’. Посетите его репозиторий GitHub, чтобы:
- Поставить вопрос о новых концепциях или свойствах, которые, по вашему мнению, следует включить.
- Предложить изменения в существующие определения.
- Участвовать в обсуждении будущего направления SEOntology.
- Примените в своей работе: Начните использовать концепции SEOntology в своих структурированных данных.
Мы доверяем открытому коду
SEOntology — это работа с открытым исходным кодом, которая идет по стопам успешных проектов, таких как Schema.org и других общих связанных словарей.
Все обсуждения и решения будут публичными, что гарантирует, что сообщество имеет право голоса в направлении SEOntology’. Когда мы наберем обороты, мы создадим комитет, который будет управлять развитием и регулярно делиться обновлениями.
Вывод и дальнейшая работа
Будущее маркетинга — это люди, а не искусственный интеллект. SEOntology – это не просто очередное модное слово – это шаг к этому будущему. SEO является стратегическим для развития методов агентивного маркетинга.
SEO больше не касается рейтингов; речь идет о создании интеллектуального, адаптивного контента и плодотворных диалогов с заинтересованными сторонами через разные каналы. Стандартизация данных и практик SEO является стратегической для построения устойчивого будущего и инвестирования в ответственный ИИ.
Готовы ли вы присоединиться к этой революции?
Есть три руководящих принципа, лежащих в основе работы SEOntology, которые мы должны объяснить читателю:
- Поскольку ИИ нуждается в семантических данных, нам нужно сделать данные SEO совместимыми, облегчая создание графов знаний для всех. SEOntology – это USB-C для данных SEO/сканирования. Важно стандартизировать данные об активах содержимого и продуктах, а также о том, как люди находят содержание, продукты и информацию в целом. Это первая цель. Здесь мы имеем два примера практического использования. У нас есть коннектор для WordLift, который получает данные сканирования от Botify сканера и помогает вам быстро запустить KG, который использует SEOntology в качестве модели данных. Мы также работаем с Advertools, сканером с открытым кодом и инструментом для оптимизации поисковых систем, чтобы сделать данные совместимыми с SEOntology;
- Продвигаясь в разработке нового агентского способа осуществления SEO и цифрового маркетинга, мы хотим влить ноу-хау SEO с помощью SEOntology, доменно-специального языка для вливания мышления SEO в SEO агенты (или многоагентные системы, такие как Agent WordLift ). В этом контексте навыки, необходимые для создания динамических внутренних ссылок, кодируются как узлы в графе знаний, а возможности становятся триггерами для активации рабочих процессов.
- Мы ожидаем, что будем работать с HITL, работающим в цикле, а это значит, что онтология станет способом совместного обмена знаниями и тактиками, которые помогут улучшить доступность поиска и предотвратить неправильное использование Generative AI, загрязняющего среду Веб сегодня.