
Узнайте, как определить каннибализацию ключевых слов с помощью встроенных текстов OpenAI. Поймите различия между разными моделями и принимайте взвешенные решения по SEO.
Эта новая серия статей посвящена работе с LLM для масштабирования ваших задач SEO. Мы надеемся помочь вам интегрировать искусственный интеллект в SEO, чтобы вы могли повысить свои навыки.
Мы надеемся, что вам понравилась предыдущая статья, и вы понимаете, что такое векторы, векторное расстояние и встраивание текста.
После этого пора напрячь свои “искусственные знания об искусственном интеллект” научившись использовать встроенные тексты, чтобы найти каннибализацию ключевых слов.
Мы начнем с текстовых вставок OpenAI’ и сравним их.
<таблица style="width: 100%;"> <тела>
(*токены можно рассматривать как слова слова.)
Но прежде чем мы начнем, вам нужно установить Python и Jupyter на вашем компьютере.
Jupyter — это веб-инструмент для профессионалов и исследователей. Это позволяет выполнять сложный анализ данных и разработку модели машинного обучения с помощью любого языка программирования.
Не волнуйтесь – это очень легко и занимает немного времени, чтобы завершить установку. И помните, что ChatGPT — ваш друг, когда речь идет о программировании.
Кратко:
- Загрузите и установите Python.
- Откройте командную строку Windows или терминал на Mac.
- Введите эти команды pip install jupyterlab и pip install notebook
- Запустите Jupiter этой командой: jupyter lab
Мы будем использовать Jupyter для экспериментов с вставкой текста; вы увидите, как весело с ним работать!
Но перед тем, как мы начнем, вы должны зарегистрироваться в OpenAI’s API и настроить выставление счетов, пополнив свой баланс.
Открыть настройки оплаты AI Api
Если вы это сделаете, настройте уведомление по электронной почте, чтобы информировать вас, когда ваши расходы превышают определенную сумму Лимиты использования.
Потом получите ключи API в Dashboard > Ключи API, которые следует хранить частными и никогда не публиковать их публично.
ключи API OpenAI
Теперь у вас есть все необходимые инструменты, чтобы начать играть со вставками.
- Откройте командный терминал компьютера и введите jupyter lab.
- Вы должны увидеть что-то вроде изображения ниже в вашем браузере.
- Нажмите Python 3 в Notebook.
jupyter lab
В открывшемся окне вы напишете свой код.
Как небольшая задача, давайте сгруппируем похожие URL-адреса из CSV. Образец CSV имеет два столбца: URL-адрес и заголовок. Задача нашего сценария состоит в том, чтобы группировать URL-адреса с похожими семантическими значениями на основе названия, чтобы мы могли объединить эти страницы в одну и исправить проблемы каннибализации ключевых слов.
Вот шаги, которые вам нужно выполнить:
Установите необходимые библиотеки Python с помощью следующих команд в терминале вашего ПК (или в ноутбуке Jupyter)
pip установить pandas openai scikit-learn numpy unidecode
&ls;openai’ библиотека нужна для взаимодействия с OpenAI API, чтобы получить встраивание, и ‘pandas’ используется для обработки данных и операций с файлами CSV.
Приложение ‘scikit-learn’ библиотека необходима для вычисления косинусного подобия, а ‘numpy’ необходим для числовых операций и обработки массивов. Наконец, unidecode используется для очистки текста.
Затем загрузите образец листа как CSV, переименуйте файл на pages.csv и загрузите его в папку Jupyter, где находится ваш сценарий.
Установите для своего ключа API OpenAI ключ, который вы получили на шаге выше, и скопируйте и вставьте следующий код в блокнот.
Запустите код, нажав значок треугольника воспроизведения в верхней части блокнота.
В задании каннибализации ключевого слова мы используем порог подобия 0,9, что означает, что если косинус подобия меньше 0,9, мы будем считать статьи разными. Чтобы визуализировать это в упрощенном двухмерном пространстве, он будет выглядеть как два вектора с углом примерно 25 градусов между ними.
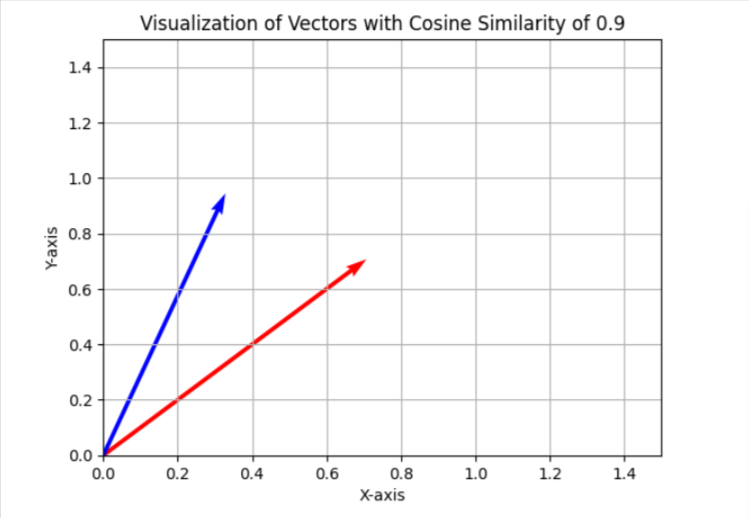
В вашем случае вы можете использовать другое пороговое значение, например 0,85 (примерно 31 градус между ними), и запустить его на выборке ваших данных, чтобы оценить результаты и общее качество совпадений. Если он неудовлетворительный, вы можете увеличить порог, чтобы сделать его более строгим для лучшей точности.
Вы можете установить ‘matplotlib’ через терминал.
pip установить matplotlib
И используйте приведенный ниже код Python в отдельном блокноте Jupyter, чтобы самостоятельно визуализировать подобия косинусов в двумерном пространстве. Попробуй это; это весело!
импортировать matplotlib.pyplot как plt импортировать numpy как np # Определите угол косинусного сходства 0,9. Измените желаемое значение. тета = np.arccos(0,9) # Определите векторы u = np.array([1, 0]) v = np.array([np.cos(тета), np.sin(тета)]) # Определите матрицу поворота на 45 градусов матрица_вращение = np.array([ [np.cos(np.pi/4), -np.sin(np.pi/4)], [np.sin(np.pi/4), np.cos(np.pi/4)] ]) # Применить вращение к обоим векторам u_rotated = np.dot(rotation_matrix, u) v_rotated = np.dot(rotation_matrix, v) # Построение векторов plt.figure() plt.quiver(0, 0, u_rotated[0], u_rotated[1], angles='xy', scale_units='xy', scale=1, color= 'r') plt.quiver(0, 0, v_rotated[0], v_rotated[1], angles='xy', scale_units='xy', scale=1, color= 'b') # Установка ограничений графика только на положительные диапазоны plt.xlim(0, 1,5) plt.ylim(0, 1,5) # Добавление меток и сетки plt.xlabel('ось X') plt.ylabel('Ось Y') plt.grid(Правда) plt.title('Визуализация векторов с косинусным подобием 0,9') # Показать сюжет plt.show()
Я обычно использую 0,9 и выше для выявления проблем каннибализации ключевых слов, но вам может понадобиться установить значение 0,5, когда вы имеете дело с перенаправлениями старых статей, поскольку старые статьи могут не иметь почти идентичных статей, которые являются более свежими, но частично близкими .
Также может быть лучше иметь мета-описание, объединенное с заголовком в случае перенаправления, в дополнение к заголовку.
Итак, это зависит от задачи, которую вы выполняете. Мы рассмотрим, как реализовать перенаправление, в отдельной статье позже в этой серии.
Теперь давайте просмотрим результаты с тремя моделями, упомянутыми выше, и увидим, как они смогли определить близкие статьи из нашей выборки данных из статей Search Engine Journal&rsquo.< /p>
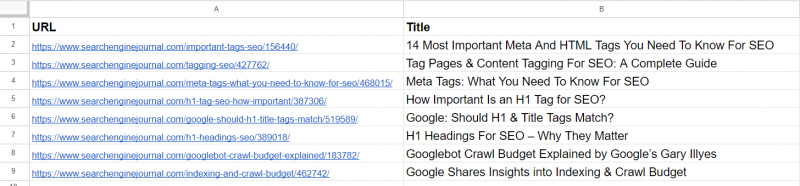
Образец данных
Из списка мы уже видим, что 2-я и 4-я статьи охватывают ту же тему ‘мета-тегов.’ Статьи в 5-й и 7-й строках почти одинаковы – обсуждение важности тегов H1 в SEO – и могут быть объединены.
Статья в 3-й строке не имеет никакого сходства с какой-либо из статей в списке, но содержит такие общие слова, как “Тег” или “SEO.”
Статья в 6-й строке снова касается H1, но не совсем так, как важность H1 для SEO. Он представляет мнение Google относительно того, должны ли они отвечать.
Статьи в 8-й и 9-й строках довольно близки, но все же разные; их можно комбинировать.
встраивание текста-ada-002
Используя ‘text-embedding-ada-002,’ мы точно нашли 2-й и 4-й статьи с косинусным подобием 0,92 и 5-й и 7-й статьи с подобием 0,91.
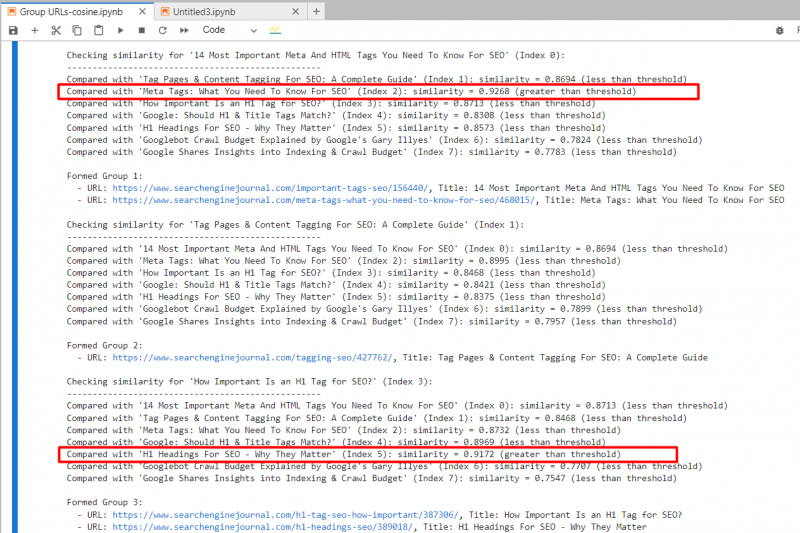
Снимок экрана из журнала Jupyter, показывающий косинус
И он создал выход с сгруппированными URL-адресами, используя тот же номер группы для подобных статей. (цвета наносятся вручную для визуализации).
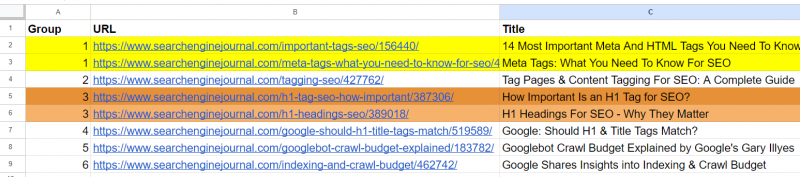
Исходящий лист с сгруппированными URL-адресами
Для 2-го и 3-го статей, которые имеют общие слова “Тег” и “SEO” но не связаны, косинусное сходство составляло 0,86. Это показывает, почему необходим высокий порог сходства 0,9 или больше. Если мы установим значение 0,85, это будет полно ложных срабатываний и может предложить объединение несвязанных статей.
текст-встраивание-3-маленький
Используя ‘text-embedding-3-small,’ довольно странно, что он не нашел никаких совпадений за нашим порогом сходства 0,9 или выше.
а для 5-го и 7-го статей с сходством 0,77.
Чтобы лучше понять эту модель путем экспериментов, я добавил несколько измененную версию 1-й строки из 15’15’ по сравнению с ’14’ к образцу.
<ол>

Пример, показывающий результаты text-embedding-3-small
Напротив, ‘text-embedding-ada-002’ дало 0,98 косинусного сходства между этими версиями.