
Этот экспертный анализ исследует этические проблемы и потенциальные преимущества ориентированного на пользователей контента ИИ для пользователей и издателей.
Повышайте свои навыки с помощью еженедельной статистики Growth Memo’ Подпишитесь бесплатно!
Стратегия Perplexity’, стоящая за новой функцией&page;Pages привела глубокий разрыв с издателями, но реакция, кажется, непропорциональна. Это намного интереснее как тематического исследования для пользовательского содержимого AI (UDC вместо UGC).< /p>
Страницы Perplexity Pages позволяют пользователям “создавать красиво оформленные исчерпывающие статьи на любую тему.” Вы можете превратить ветвь, последовательность подсказок, на страницу, посвященную теме. -контент, который занимает рейтинг в обычном поиске и приводит посетителей к pleplexity.ai, который превращается в платных подписчиков.
Стратегия роста вписывается в то, что генеральный директор Сринивас объясняет как «агрегатор информации».”1 Он держит власть, обеспечивая превосходное взаимодействие с пользователем, что позволяет направлять спрос и превращать предложение в товары. .
Бросить в ведро
Когда мы смотрим на фактические данные, мы видим, что реакция СМИ избыточна. Не в критике, а во влиянии. Справедливо попросить Perplexity настроить атрибуцию, соблюдать веб-стандарты, такие как robots.txt, и использовать официальные IP-адреса, как это делают поисковые системы.
По словам разработчика Райана Найта, Perplexity сканирует Интернет с помощью безголового браузера, который маскирует его строку IP.2
Генеральный директор Шринивас сказал, что Perplexity подчиняется robots.txt, а замаскированный IP-адрес поступил от посторонней службы. Но он также отметил, что появление искусственного интеллекта требует нового типа рабочих отношений между создателями контента или издателями и сайтами, подобными ему. rdquo;
Но с точки зрения преимуществ для Perplexity, Pages — это капля в море.

Автор изображения: Кевин Индиг
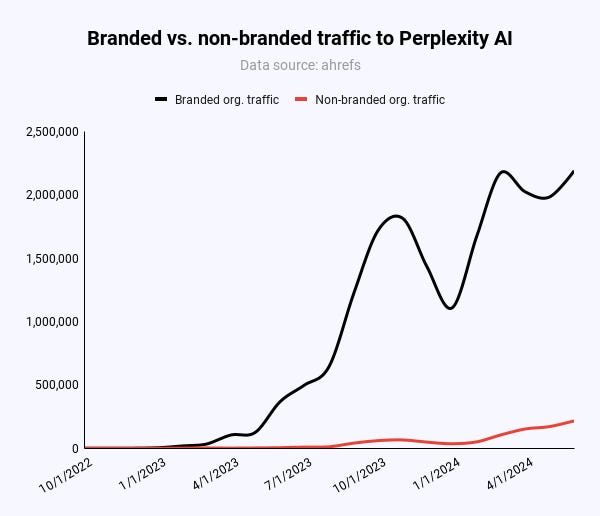
91% органического трафика к perplexity.ai происходит от фирменных терминов, таких как “perplexity.”< /p>
Только 47 000 из 217 000 (21,6%) ежемесячных посетителей Страниц приходят из обычных, небрендированных ключевых слов во всем мире.
В США это 55% (20 000/36 000). Однако, по сравнению с x посещениями в месяц через фирменные сроки, Pages не делает никакого удара в органическом трафике Perplexity.
Автор изображения: Кевин
На самом деле большинство трафика на Perplexity поступает через его бренд и по устной информации. Недавнее освещение в СМИ могло больше помочь Perplexity, чем повредить. По данным Similarweb, с января 2024 года каждый день этот сайт достигал новых рекордов трафика.
Весь домен Perplexity’ имеет только 950 страниц, из которых Страницы составляют около 600. По сравнению с другими сайтами – как 6,8 миллиона статей Википедии только в английской версии – это просто не так уж много. По мере того, как страницы получат больше тяги, появятся более сильные эффекты масштаба. Pages — это бета-функция, которая зарождается.
Если внимательнее рассмотреть его эффективность, то страницы с наиболее часто ищущими ключевыми словами вошли в топ-3 по запросу “была ли виновата конфета Монтгомери&quo;rdquo; (600 MSV). Самым сложным ключевым словом, которое он занимает первую позицию, является “когда была первая покупка биткойнов” (KD: 76, MSV: 30). Другими словами, Pages еще должен пройти долгий путь.
Сравнение сходства текста n=1 (!) из GoTranscript между страницей Perplexity’ для “биткойн-пиццы дня” и его четыре связанных источника показывают&m;nbsp;мало доказательств плагиата:
<ол>

Сравнение текста между статьями Perplexity’s и NationalToday’s о Дне биткой Индиг )
“пропавший” Кажется, проблема атрибуции была исправлена, как показано в примере ниже.
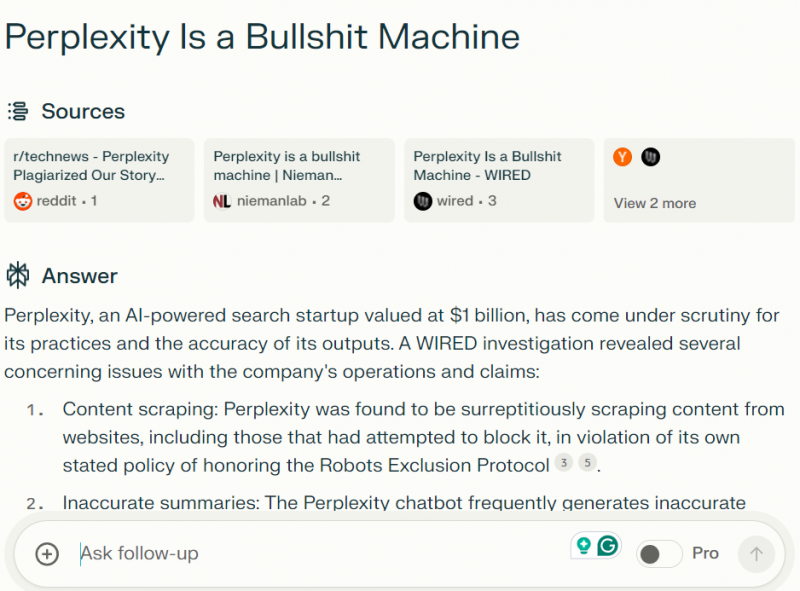
Perplexity выделяет источники для ответов в верхней части (автор изображения: Кевин Индий <цитата>
Результаты показали, что чат-бот иногда точно перефразировал истории WIRED, а порой обобщал истории неточно и с минимальной ссылкой на авторство.
< /blockquote>
Я не смог подтвердить или опровергнуть случаи галлюцинаций, но ожидаю, что лучшие модели дойдут до точки, когда они смогут безупречно обобщить существующее содержимое. Реальность такова, что мы еще не там. Обзоры искусственного интеллекта Google также показали, что содержат неправильные факты или придумывают вещи.
Google, кажется, смог быстро решить эту проблему, поэтому я ожидаю, что степень галлюцинаций снизится.
Одним из основных вопросов критики плагиата является то, что поиск по точному названию статьи возвращает эту статью.
Конечно, Perplexity должно возвращать краткое изложение статьи, когда пользователи спрашивают это. Что еще должно показать Perplexity? Тот же аргумент возник в иске между OpenAI и NY Times.
Запущено
Кроме проблем со сканированием, которые Perplexity должна решить, реакция СМИ, похоже, вызвана позиционированием Perplexity.
Одно предложение в анонсе Perplexity’ Pages добирается до сути основной проблемы:
“С Pages вам не’нужно быть опытным писателем, чтобы создавать высококачественное содержимое.”4
На странице также упоминается:
<цитата>
”Создать резонансное содержимое может быть трудно. Pages создан для ясности, разбивая сложные темы на легкоусвояемые части и обслуживая всех, от преподавателей до руководителей.&rd;5-60~/p><
Все примеры страниц, приведенные в объявлении, касаются “как” или “что такое” темы:
- “Руководство по игре на барабанах для начинающих”
- “Как пользоваться AeroPress”
- “Написание Kubernetes CronJobs”
- “Стив Джобс: дальновидный генеральный директор”
- И т.д.
Это именно тот вызов, который ИИ ставит перед авторами: ИИ может все больше охватывать четко определенные форматы содержимого, такие как руководства или учебники. Я вижу, как это вызывает у журналистов.
Пользовательское содержимое
Обратите внимание, что Perplexity не&r;quo; создает все содержимое для страниц, но получает~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <стр.>Вместо того, чтобы писать целую статью, люди собирают фрагменты пазла вместе со штампом их автора на странице.
Я ожидаю, что то же самое произойдет с другими типами содержимого, такими как обзоры и платформы, такие как Google, Tripadvisor, Yelp, G2 & Co., чтобы предоставить соответствующие инструменты для облегчения создания содержимого. Наибольшей проблемой будет поддерживать высокое качество и свести к минимуму ненужную информацию.
Большой вопрос заключается в том, может ли такая конструкция, как Pages, конкурировать с чисто рукотворным сайтом, таким как Википедия, которая имеет 116 000 активных участников.6
Чем больше “Игра роста” по страницам (IMHO) — это то, как Perplexity создает искусственный интеллект (видео) подкасты из обобщенных статей, которые опережают оригинальные результаты.
<цитата>
“Потом Perplexity прислала эту подделку своим подписчикам с помощью мобильного push-сообщения. Он создал подкаст, сгенерированный искусственным интеллектом, используя ту же отчетность (Forbes) — без какого-либо упоминания Forbes, и это стало видео YouTube, которое опережает все содержимое Forbes на эту тему в поиске Google.
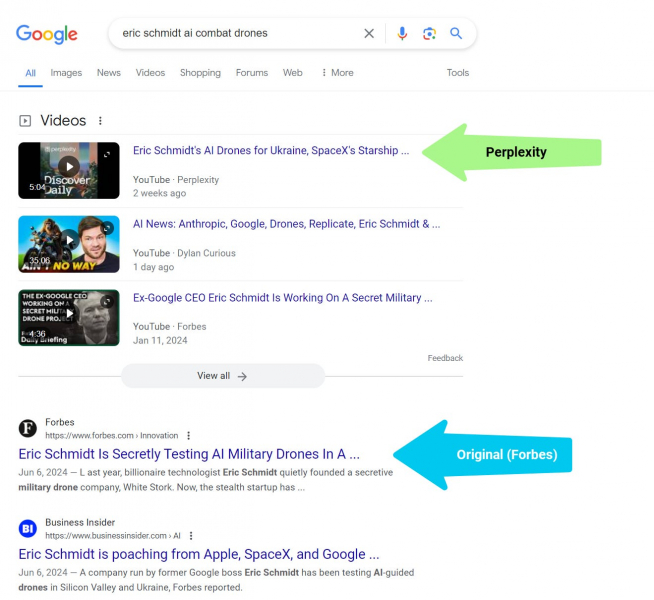
Perplexity опережает издателей с помощью видеоподкастов с обобщением статей (Автор изображения: Кевин Индиг)
Google придется выяснить, как помешать LLM-ам перепрофилировать содержимое издателей.
После изучения фактов остается осознание того, насколько трудно балансировать, предоставляя ИИ отвечать при отправке трафика к источникам. Зачем пользователям нажимать, когда на большинство их вопросов есть ответы?
С другой стороны медали, издатели сами могут предоставлять резюме своих статей. Поэтому главная задача для Perplexity – и любой другой, кто хочет создать масштабный AI-контент для Поиска – добавляет уникальную ценность в дополнение к итогам AI.
Персонализация
Путь к уникальной ценности итогов AI и другого содержания AI — это персонализация.
Система, которая может распознавать ваши предпочтения относительно уровня понимания темы, может сделать свод AI более полезным для вас. Perplexity — это обертка вокруг разных LLM, но если она собирает значительную информацию о пользователях и персонализирует результат, она может добавить ценности, кроме быстрых ответов.
Производители операционных систем устройств, такие как Alphabet и Apple, имеют наибольшее преимущество, когда дело доходит до данных пользователей, поскольку они находятся на вершине пищевой цепи.
Ярким примером является Apple Intelligence, которая, вероятно, может ответить на вопросы, которые сейчас предлагаются в руководствах и учебниках на Google или Perplexity.
Apple Intelligence (сокращенно “AI” – приятно, Apple!) имеет полный контекст через местонахождение (Apple Maps), использование посторонних программ, подсказки Siri, электронную почту (Apple Mail) и другие источники, что создает хорошую базу для персонализации результатов. Сеть — это лишь один из источников знаний, и гораздо более сексуальный из них ждет в наших Dropbox, Gmail и фотографиях на iPhone.
Сегодня персонализированные ответы — это видение и демонстрация.
Но в какой-то момент в будущем персонализация даст лучшие ответы, чем любой общий итог LLM и, конечно, больше, чем любое руководство, написанное человеком.
Ценность определенных и общих знаний заключается в курсе столкновения с бомбардировщиками LLM. В то же время ценность персонализированных знаний, человеческого опыта и заслуживающей доверия экспертной экспертизы резко возрастает.
1 Стартап с искусственным интеллектом Perplexity хочет перевернуть поисковый бизнес. Издание Forbes говорит, что это обманывает их; Рост интегратора против агрегатора
2 Perplexity AI лжет о своем агенте пользователя
3 Генеральный директор Perplexity Аравинд Шринивас отвечает на обвинения в плагиате и нарушении прав
4 Что такое Perplexity Pages?
5 Знакомство со страницами Perplexity
6 Википедия:Про
7 Почему циничная кража Perplexity&rsquo представляет все, что может пойти не так с ИИ