
Узнайте, как проверить свои теории SEO с помощью Python. Узнайте шаги, необходимые для предварительного тестирования факторов рейтинга поисковой системы и проверки внедрения на всем сайте.
При работе на сайтах с трафиком можно потерять столько же, сколько и получить от внедрения рекомендаций SEO.
Негативный риск неправильной реализации SEO можно уменьшить с помощью моделей машинного обучения для предварительного тестирования факторов рейтинга поисковых систем.
Несмотря на предварительное тестирование, сплит-тестирование является самым надежным способом проверить теории SEO перед тем, как решать развертывать внедрение на всем сайте или нет.
Мы рассмотрим шаги, необходимые для использования Python для проверки ваших теорий SEO.
Выберите ранговые позиции
Одной из проблем проверки теорий SEO являются большие размеры выборки, необходимые для статистически достоверных выводов теста.
Сплит-тесты – популяризировал Уилл Кричлоу с SearchPilot – отдавайте предпочтение показателям, основанным на трафике, таким как клики, что хорошо, если ваша компания корпоративного уровня или имеет большой трафик.
Если на вашем сайте нет такой завистливой роскоши, то трафик как показатель результата, скорее всего, будет относительно редким событием, а это значит, что ваши эксперименты будут длиться слишком долго, чтобы проводить и тестировать.< /p>
Вместо этого учитывайте ранговые должности. Достаточно часто для компаний малого и среднего размера, стремящихся развиваться, их страницы часто оцениваются по целевым ключевым словам, которые еще не имеют достаточно высокого рейтинга, чтобы получить трафик.
В течение периода времени вашего теста для каждого момента времени, например дня, недели или месяца, вероятно, будет несколько точек данных позиции в рейтинге для нескольких ключевых слов. По сравнению с использованием метрики трафика (который, вероятно, будет гораздо меньше данных на страницу за дату), что сокращает период времени, необходимый для достижения минимального размера выборки, если используется позиция в рейтинге.
Таким образом, ранговая позиция прекрасна для клиентов некорпоративного размера, желающих проводить сплит-тесты SEO, которые могут достичь понимания гораздо быстрее.
Google Search Console — ваш друг
Решение использовать позиции рейтинга в Google делает использование источника данных простым (и удобно недорогим) решением в Google Search Console (GSC), если предположить, что он настроен.< /p>
GSC хорошо подходит, поскольку он имеет API, который позволяет добывать тысячи точек данных со временем и фильтровать строки URL.
Хотя данные могут не соответствовать евангельской истине, они по крайней мере будут последовательными, что вполне достаточно.
Заполнение отсутствующих данных
GSC отчитывается только о данных для URL-адресов, которые имеют страницы, поэтому вам’ нужно будет создать строки для дат и заполнить недостающие данные.
Используемые функции Python будут комбинацией merge() (например, функция VLOOKUP в Excel), которая используется для добавления отсутствующих строк данных на URL-адрес и заполнения данных, которые вы хотите ввести для этих отсутствующих дат в этих URL -адресах .
Для показателей трафика это ’будет нулевым, тогда как для позиций в рейтинге это’будет или средним значением (если вы’предполагаете, что URL-адрес имел рейтинг, когда не было сгенерировано показов), или 100 (до допустим, что это не было рейтингом).
Код приведен здесь.
Проверьте распределение и выберите модель
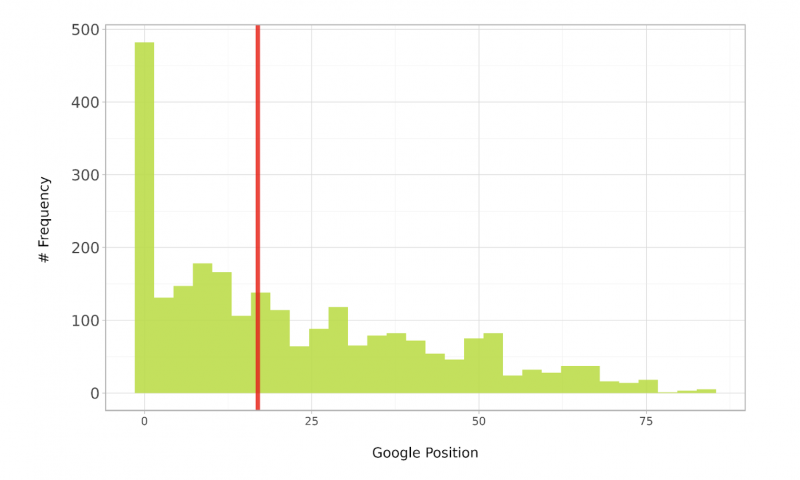
Распределение каких-либо данных отражает их природу с точки зрения того, где наиболее популярно значение (режим) для данной метрики, скажем, ранговая позиция (в нашем случае выбрана метрика) для данной выборочной совокупности.
Распределение также покажет нам, насколько близки остальные точки данных к середине (среднего значения или медианы), т.е. p>Это критически важно, поскольку это повлияет на выбор модели при оценке вашего теста по теории SEO.
Используя Python это можно сделать как визуально, так и аналитически; визуально, выполнив этот код:
ab_dist_box_plt = ( ggplot(ab_expanded.loc[ab_expanded[&position'].between(1, 90)], aes(x = &position')) + geom_histogram(альфа = 0,9, контейнеры = 30, заливка = “#b5de2b”) + geom_vline(xintercept=ab_expanded[&position'].median(), color=”red”, alpha = 0.8, size=2) + labs(y = '# Частота n', x = 'nПозиция Google') + scale_y_continuous(labels=lambda x: ['{:,.0f}'.format(label) for label in x]) + #coord_flip() + theme_light() + theme(legend_position = 'bottom', axis_text_y = element_text (rotation = 0, hjust = 1, size = 12), legend_title = element_blank() ) ) ab_dist_box_plt
pip установить pandas plotnine:
Теперь мы знаем, какую тестовую статистику использовать, чтобы определить, следует ли придерживаться теории SEO. В этом случае существует выбор моделей, подходящих для этого типа распределения.
Минимальный размер выборки
Выбранную модель также можно использовать для определения минимального необходимого размера выборки.
Необходимый минимальный размер выборки гарантирует, что любые наблюдаемые различия между группами (если таковые есть) являются реальными, а не случайными.
То есть разница в результате вашего эксперимента или гипотезы SEO является статистически значимой, и вероятность того, что тест правильно сообщит о разнице, высока (известна как мощность).
Это может быть достигнуто моделированием ряда случайных распределений, соответствующих приведенному выше шаблону как для теста, так и для контроля, и выполнения тестов.
Код приведен здесь.
При запуске кода мы видим следующее:
(0,0, 0,05) 0 (9,667, 1,0) 10000 (17,0, 1,0) 20000 (23,0, 1,0) 30000 (28,333, 1,0) 40000 (38,0, 1,0) 50000 (39.333, 1.0) 60000 (41,667, 1,0) 70000 (54.333, 1.0) 80000 (51.333, 1.0) 90000 (59,667, 1,0) 100000 (63,0, 1,0) 110 000 (68.333, 1.0) 120000 (72.333, 1.0) 130000 (76.333, 1.0) 140000 (79,667, 1,0) 150000 (81.667, 1.0) 160000 (82.667, 1.0) 170000 (85.333, 1.0) 180000 (91,0, 1,0) 190000 (88,667, 1,0) 200000 (90,0, 1,0) 210000 (90,0, 1,0) 220000 (92,0, 1,0) 230000
Чтобы разбить это, числа представляют следующее, используя пример ниже:
(39.333,: доля прогонов моделирования или экспериментов, в которых будет достигнута значимость, то есть последовательность достижения значимости и надежности.
1.0) : статистическая мощность, вероятность того, что тест правильно отклоняет нулевую гипотезу, то есть эксперимент разработан таким образом, что разница будет правильно обнаружена на этом уровне размера выборки.
60000: размер выборки
Вышеприведенное является интересным и потенциально запутанным для нестатистов. С одной стороны, это свидетельствует о том, что нам понадобится 230 000 точек данных (сделанных из ранговых точек данных в течение периода времени), чтобы иметь 92% шанс наблюдать за экспериментами SEO, достигающими статистическую значимость. Однако, с другой стороны, имея 10 000 точек данных, мы достигнем статистической значимости – Итак, что нам делать?
Опыт научил меня, что вы можете достичь значимости преждевременно, поэтому вы будете стремиться к размеру выборки, который вероятно, будет удерживать по меньшей мере 90% времени – Нам понадобится 220 000 точек данных.
Это действительно важный момент, потому что, научив несколько корпоративных команд SEO, все они жаловались на проведение убедительных тестов, которые не дали желаемых результатов при внедрении выигрышных тестовых изменений.
Следовательно, описанный выше процесс позволит избежать всей этой душевной боли, напрасно потраченного времени, ресурсов и подведенного доверия по незнанию минимального размера выборки и преждевременному прекращению тестов.
Назначить и реализовать
Учитывая это, теперь мы можем начать назначать URL-адреса между тестовой и контрольной, чтобы проверить нашу теорию SEO.
В Python мы& rsquo;будем использовать функцию np.where() (расширенная функция IF в Excel), где мы имеем несколько вариантов разделения наших предметов по шаблону URL-адреса строки, типу содержимого , ключевыми словами в заголовке или другим в зависимости от теории SEO, которую вы хотите подтвердить.
Используйте приведенный здесь код Python.
Строго говоря, вы запустили бы это, чтобы собрать данные в будущем как часть нового эксперимента. Но вы можете проверить свою теорию ретроспективно, предполагая, что нет других изменений, которые могли бы взаимодействовать с гипотезой и изменить валидность теста.
О чем следует помнить, поскольку это несколько предположение!
Тест
Если данные будут собраны или вы уверены, что имеете исторические данные, вы готовы к запуску теста.
В нашем случае ранговой позиции мы, скорее всего, будем использовать модель, подобную тесту Манна-Уитни, из-за его свойств распределения.
Однако, если вы используете другую метрику, такую как клики, которая, например, является распределением Пуассона, тогда вам нужна будет совсем другая статистическая модель.
Код для запуска теста приведен здесь.
После запуска вы можете напечатать результаты теста:
U-тест Манна-Уитни Результаты теста Статистика MWU: 6870,0 P-значение: 0,013576443923420183 Дополнительная итоговая статистика: Тестовая группа: n=122, среднее=5,87, стандартное значение=2,37 Контрольная группа: n=3340, среднее=22,58, стандартное значение=20,59
Приведенное выше является результатом проведенного мной эксперимента, который показал влияние коммерческих целевых страниц со вспомогательными пособиями блогов со внутренними ссылками на первые и неподдерживаемые целевыми страницами.
В этом случае мы показали, что страницы предложений, поддерживающих контент-маркетинг, имеют более высокий рейтинг у Google в среднем на 17 позиций (22,58 – 5,87). Разница также значительна — 98%!
Однако нам нужно больше времени, чтобы получить больше данных &nd; в этом случае еще 210000 точек данных. Как и с текущим размером выборки, мы можем быть уверены лишь в том, что 10% времени теория SEO воспроизводима.
Сплит-тестирование может продемонстрировать навыки, знания и опыт
В этой статье мы ознакомились с процессом тестирования ваших гипотез SEO, охватывая требования к мышлению и данным для проведения действительного теста SEO.
Теперь вы можете понять, что есть много, что нужно распаковать и учитывать при разработке, выполнении и оценке тестов SEO. Мой видеокурс «Data Science for SEO» гораздо глубже (с дополнительным кодом) рассказывает о науке SEO-тестов, включая разделенные A/A и разделенные A/B.
Как специалисты по оптимизации поисковых систем, мы можем воспринимать определенные знания как должное, например влияние контент-маркетинга на эффективность оптимизации поисковых систем.
Клиенты, с другой стороны, часто ставят под сомнение наши знания, поэтому методы сплит-теста могут быть наиболее удобными для демонстрации ваших навыков, знаний и опыта SEO!