
В этой статье я хотел бы поговорить о том, почему вы могли бы предпочесть использование Arc<[T]> вместо Vec<T> в качестве варианта по умолчанию в вашем Rust-коде.
Используйте Arc<[T]> вместо Vec<T>
Arc<[T]> может быть очень хорошей заменой Vec<T> для иммутабельных данных. Так, если вы формируете большую последовательность данных, которые потом никогда не будете менять в последствии, вы можете подумать в сторону Arc<[T]>. Также он действительно хорош если вы планируете хранить болшое множество таких объектов; или планируете просто массово перемещать или копировать их в процессе работы программы.
Я сейчас не говорю о Vec<T>, который вы сформировали в качестве локальной переменной внутри функции или который будет использоваться как что-то временное. Речь скорее о таких случаях, когда вы планируете хранить данные в течение долгого промежутка времени, особенно если данные реализуют Clone.
Это не должно быть большим открытием, так как Clone — что-то вроде супер-способности Arc, о которой мы сейчас вкратце поговорим. Если вы собираетесь постоянно копировать огромные последовательности иммутабельных данных, Arc может серьезно ускорить эту операцию в сравнении с Vec<T>. Вы даже можете пойти дальше и использовать Box<[T]>, но об этом мы поговорим в самом конце.
Примечание переводчика
Далее по тексту часто будет употребляться термин “копирование”, но в этой статье под ним подразумевается исключительно операция
Clone::clone()— не перепутайте с трейтомCopy!
Почему Arc<[T]>?
Итак, почему я рекомендую Arc<[T]>? Для этого есть три веских причины. Первую мы уже немного успели затронуть. У Arc дешевое копирование, выполняемое за константное время. То есть неважно, насколько у вас большие данные, на которые указывает Arc, их копирование всегда займет одинаковое время — время инкремента целочисленной переменной и копирования самого Arc-указателя. И это выполняется очень, очень быстро и не задействует никакого выделения памяти, которое обычно происходит при копировании Vec. Это весомая оптимизация, которую можно получить просто перейдя на Arc<[T]>.
Другая причина — Arc<[T]> занимает всего 16 байт; он хранит только указатель и размер данных, в отличие от Vec<T>, которому нужно хранить указатель, size и capacity, что в общей сложности составляет 24 байта. Разница всего в восемь байт — это немного — но если вы храните огромное количество таких контейнеров, особенно в структуре или в массиве, то в случае с Vec<T> это дополнительное место может суммироваться и ухудшить ваш cache locality, и проход по вашим данным будет чуточку труднее и медленнее.
Наконец, третья причина — Arc<[T]> реализует трейт Deref<[T]>, так же как это делает Vec<T>. То есть, вы можете совершать все те же read-only операции c Arc<[T]>, какие вы делали с Vec<T>. Вы можете взять его длину, проитерироваться или обратиться по индексу. Это важно, поскольку первые два довода хороши, но я бы, пожалуй, не стал из-за них рекомендовать переход на Arc<[T]>, если бы его было куда труднее использовать, нежели Vec<T>, но это не так благодаря Deref<[T]>.
Arc так же реализует большое количество других трейтов, которые могли бы вам понадобиться, и все это делает Arc<[T]> взаимозаменяемым с Vec<T> в большинстве обстоятельств.
Таким образом, первые два преимущества — скорее про некоторый прирост производительности; третье же про то, что использовать Arc<[T]> не труднее, чем Vec<T>, так что вам будет достаточно просто сделать быстрый рефакторинг и перейти на Arc<[T]>.
Arc<str> vs String
Итак, мы поговорили про Arc<[T]> в сравнении с Vec<T>. Оставшуюся же часть статьи я буду говорить про Arc<str> и его преимущество в сравнении со String, ведь эта пара разделяет схожую дихотомию. Но на ее примере немного проще показать суть и использовать более жизненные примеры. А в целом, все, что я скажу про Arc<str> vs String будет относиться и непосредственно к Arc<[T]> vs Vec<T>.
Также заслуживает упоминания, что когда вы планируете использовать Arc, сперва попробуйте использовать Rc. Например, если вам не нужна потокобезопасность, которую вам дает Arc. Повествование отдает все лавры Arc только потому, что это более общая версия подхода, но если вам подойдет и Rc, вы определенно должны использовать именно его, так как он имеет меньший оверхед в сравнении с Arc.
Стоит прояснить еще кое-что. Я хочу уточнить, что говорю об Arc<str> — не об Arc<String>. Arc<String> на самом деле имеет некоторые преимущества над Arc<str>, но с другой стороны имеет и очень существенные недостаток: вам нужна косвенность в целых два указателя чтобы добраться до данных, которые вам нужны — до символьных данных строки. Я покажу визуализацию этой ситуации в конце, но Arc<String> в общем целом — это просто громоздко и неэффективно по памяти, а вышеупомянутая двойная косвенность серьезно ударяет по производительности, поэтому я не рекомендую использовать Arc<String>.
Поэтому мы будем говорить конкретно про Arc<str>. Сила “толстых” указателей (wide pointers) в Rust заключается в том, что Arc имеет возможность указывать непосредственно на динамически выделенный на куче текстовый буфер.
MonsterId
Представим, что я работаю над игрой, и у меня есть тип struct MonsterId(String). Под капотом он представлен как обычный текст, и я, как мы видим, использую String, чтобы хранить его.
Примечание переводчика
У меня сложилось стойкое впечатление, что автор оригинального видео скорее имел в виду
MonsterType, нежелиMonsterId, поскольку большинство дальнейших примеров и использованийMonsterIdнамекают на то, что подразумевается не конкретный созданный монстр, а скорее его разновидность.Тем не менее, продолжим использовать
MonsterIdв дальнейшем повествовании, чтобы отдать дань оригиналу, при этом держа в уме, что если у вас немного не складывается картина, то вы можете мысленно заменитьMonsterIdнаMonsterType, и, возможно, вы почувствуете облегчение.
Первое, что я мог бы захотеть реализовать для моего MonsterId, это пачку типичных трейтов:
#[derive(Clone, Debug, PartialEq, Eq, Hash, Ord, PartialOrd, Serialize, Deserialize, /* ... */)] struct MonsterId(String); Как видим, я хочу иметь возможность копировать наш id, выводить на экран его дебажное представление, сравнивать его, хэшировать. Также я хочу использовать serde для сериализации и десериализации, возможно из конфига или из каких-то save-данных. В общем, я хочу отнаследовать все эти трейты для моего MonsterId, и чтобы это все работало со String.
Далее, я хочу метод для MonsterId, который просто выдает внутреннее текстовое представление в качестве &str. Возможно, я хочу логгировать его в консоль, возможно, я хочу использовать его для аналитики в каком-то другом месте:
fn as_str(&self) -> &str { &self.0 } То есть я просто хочу достучаться до внутреннего представления данных в виде &str, и это достаточно легко сделать, имея String.
Далее, мне понадобится конфиг с данными в виде HashMap с MonsterId в качестве ключа и некоторыми статами в качестве данных — ну, вы знаете: урон монстра, его здоровье и прочее подобное:
enemy_data: HashMap<MonsterId, EnemyStats> Ключ — MonsterId, именно поэтому мне нужна была реализация Eq и Hash, и все это отлично работает со String в качестве внутреннего представления MondterId.
Следующее, что нам могло бы понадобиться — хранить в списке идентификаторы всех врагов, которые когда-либо спавнились за одну игровую сессию:
enemies_spawned: Vec<MonsterId> Заметьте, что я здесь использую Vec<T>, поскольку предполагается, что монстры будут добавляться сюда в процессе игры, и мне, вероятно, придется копировать сюда MonsterId. Список может быть ощутимо бóльшим.
Далее, нужна какая-то функциональность для создания реального монстра по MonsterId:
fn create(id: MonsterId) -> EnemyInstance { ... } Вероятно, я собираюсь копировать MonsterId в эту функцию, возможно, копировать MonsterId внутрь инстанса монстра, чтобы каждый монстр знал, кто он такой.
И, наконец, скажем, я буду хранить какую-то статистику внутри BTreeMap — например, сколько раз определенный MonsterId был убит в процессе игровой сессии.
total_destroyed: BTreeMap<MonsterId, u64> Я использую здесь BTreeMap просто, чтобы он отличался от уже используемого нами HashMap, и у нас есть возможность использовать MonsterId в качестве ключа в BTreeMap потому что он реализует Ord.
В общем, тут достаточное количество разнообразных кейсов; ну и конечно их может быть куда больше. Это просто пример того, как такой базовый тип как MonsterId может начать пронизывать всю вашу систему, и вам придется повсюду его копировать в процессе работы программы. В какой-то момент вам может понадобиться использовать все эти вышеперечисленные структуры разом, и даже больше, и в какой-то момент все эти операции по копированию MonsterId начнут сказываться на производительности, и все это станет расти, как снежный ком.
String
Итак, давайте посмотрим на стоимость копирования MonsterId и его общее потребление памяти при использовании String в качестве внутреннего представления. Вот как String представлен в памяти:
Реальные текстовые данные в String представлены как последовательность символов на куче, и String выделяет достаточное количество памяти под ваш текст, что очевидно, но так же он выделяет еще немного места, чтобы строка могла расти до какого-то предела без повторного выделения памяти.
У нас есть строка “Goblin”

с дополнительными незанятыми четырьмя байтами памяти для случая, если String станет длиннее, хотя, конечно, в конкретном случае мы знаем, что этого не произойдет, поскольку Goblin — это окончательное имя монстра.
Далее, сам объект String состоит из трех восьми-байтовых полей:
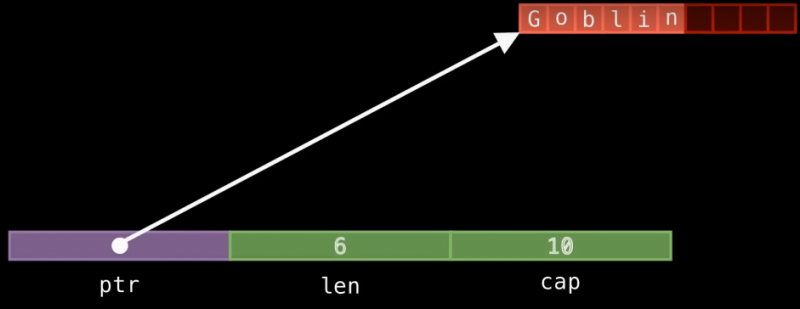
-
указателя на данные
ptr -
длины данных
len -
вместимости
cap
ptr указывает непосредственно на выделенную для нашей строки память, len хранит размер текста “g-o-b-l-i-n”, то есть равен шести, а cap включает в себя размер всей выделенной для объекта памяти и в нашем случае равен десяти.
Теперь давайте посмотрим, как выглядит копирование String. Сначала нам нужно целиком продублировать массив символов. Для этого будет выделен новый участок памяти на куче, а затем все символы будут скопированы в него, что займет линейное время выполнения — другими словами, это займет тем больше времени, чем длиннее ваша строка. Потом будет создан новый объект String на стеке, и он будет ссылаться на новый массив символов на куче.
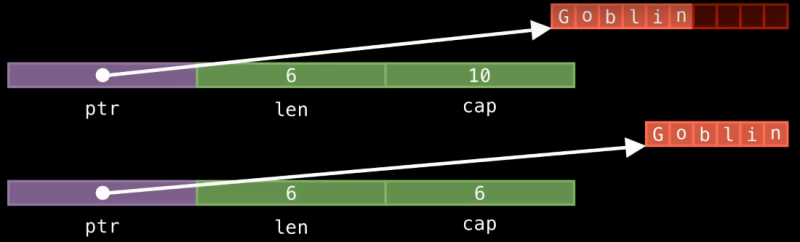
Заметьте, что в этот раз резервное место для строки было отброшено, поскольку дубликат строки скорее всего не будет расти, и у нас получается полностью заполненный буфер с данными. Поэтому в данном случае мы получаем cap, равный шести — и он избыточен, поскольку теперь он идентичен с len.
Если мы хотим сделать еще одну копию, нам придется повторить все то же самое: выделить память под новый буфер, скопировать в него все символы строки, а затем создать на стеке объект String, который будет ссылаться на него. И у нас снова будет избыточное, не нужное нам поле cap.
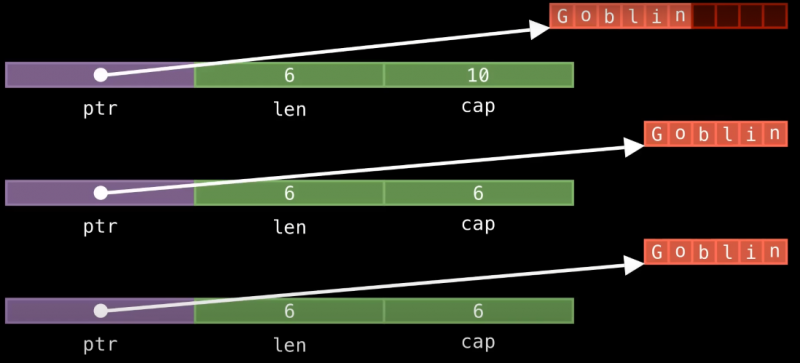
Полагаю, вы понимаете, что процесс выделения памяти — достаточно дорогая операция, а объекты String занимают больше места, чем хотелось бы для нашей простой задачи по хранению гоблинов.
Arc<str>
Теперь, давайте посмотрим на этот же случай, но с использованием Arc<str> вместо String. С Arc<str> данные на куче выглядят немного иначе, чем в случае со String:

Итак, у нас присутствуют два восьми-байтных поля: одно для подсчета сильных ссылок, другое — для подсчета слабых, затем идут реальные текстовые данные. На данном этапе это выглядит длинно и странновато, но не волнуйтесь, станет лучше.
Наш объект Arc на стеке состоит всего лишь из указателя и длины данных:

Это всего 16 байт, поскольку отсутствует дополнительное поле capacity, которое было у String. Давайте посмотрим, что произойдет при копировании:
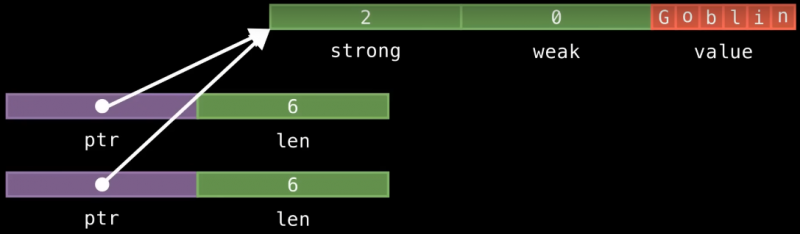
Все, что нам пришлось сделать — это скопировать структуру на стеке и инкрементировать счетчик ссылок, который теперь равен двум. Заметьте, мы не произвели никакого выделения новой памяти; мы не делали глубокого копирования текстовых данных, как в String. Мы просто ссылаемся на все те же текстовые данные в двух разных местах.
То есть мы теперь можем очень и очень дешево делать копии:
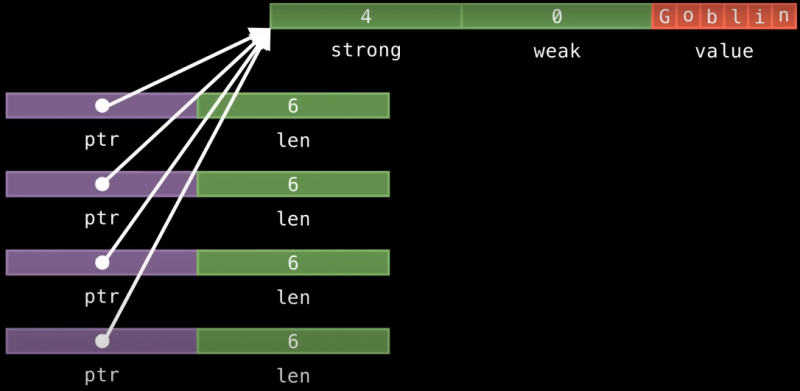
И тот факт, что текстовые данные делятся между разными Arc-объектами также увеличивает шансы, что они будут в кэше, когда мы их запросим, потому что они загружаются в кэш каждый раз, когда я использую любой из четырех Arc-объектов с изображения выше. В отличие от String, где память, на которую мы указываем, была бы загружена в кэш только если мы недавно читали из этого конкретного объекта String.
Видно, что этот подход в целом легковеснее. Arc-указатели сами по себе меньше, то есть в идентичное количество памяти может уместиться большее их количество, и, честно говоря, я считаю, что это просто более грамотное использование ресурсов для иммутабельных строк, которые копируются по всему нашему коду.
Также, эти два дополнительных поля — strong и weak — за которые мы платим на куче, изолированы от каждого отдельного имеющегося у нас Arc-объекта, поэтому их присутствие как бы амортизируется, тогда как в случае со String мы вынуждены платить за каждое такое поле, потому что оно лежит на стеке. Это два дополнительных поля на куче — а два, конечно, больше, чем один — но они все-таки делятся между каждым инстансом Arc-объекта, ссылающегося на нашу строку. Так что в конечном счете это намного меньший расход памяти в сравнении со String.
Итак, давайте посмотрим, как выглядит и ощущается переход со String на Arc<str> для MonsterId:
#[derive(Clone, Debug, PartialEq, Eq, Hash, Ord, PartialOrd, Serialize, Deserialize, /* ... */)] struct MonsterId(Arc<str>); Во-первых, все наши имплементированные трейты работают так же, как и работали ранее. Вы можете копировать Arc<str>, выводить дебажный принт Arc<str>, сравнивать его, хешировать. Вы также можете сериализовать и десериализовать его. Все это работает точно так же, как работало раньше.
Что по поводу доступа непосредственно к текстовым данным? Метод as_str() не придется менять, потому что Arc<str> реализует Deref<str> так же, как и String. Мы можем просто взять ссылку на него и она автоматически превратится в &str. То есть, ничего в этой функции тоже не нужно менять — она работает идеально.
Далее, что с нашим словарем HashMap<MonsterId, EnemyStats>? Ну, наш объект MonsterId все еще реализует Eq и Hash, потому что Arc<str> тоже реализует их, поэтому и здесь ничего не надо менять.
Фактически, я бы поспорил, что из-за все этого в данном случае использование Arc<str> более оправдано, чем использование String, поскольку String дает вам обширное API для модификации внутреннего текстового представления, но вы не можете модифицировать ключ HashMap, потому что вы можете сломать инвариантность данных. Представление вашего ключа как иммутабельного типа вроде Arc<str>, является более подходящим в данной ситуации, нежели String.
Двигаемся дальше. Мой Vec<MonsterId> станет теперь более cache-friendly, потому что я убрал целое лишнее поле для каждого MonsterId, а это две трети от старого размера MonsterId. Моя функция создания инстанса врага по MonsterId, вероятно, теперь более эффективна, поскольку, я так полагаю, она вовлекает в той или иной степени копирование, которое теперь делается эффективнее с Arc.
И, наконец, наша BTreeMap — с ней по сути все тоже самое, что и с HashMap; использование иммутабельных данных, таких, как наш Arc<str>, просто более подходяще для нашего ключа, поскольку ключи BTreeMap в любом случае нельзя модифицировать. BTreeMap теперь будет эффективнее, поскольку хранит меньшее количество данных и не должна платить за риски быть мутабельной тогда, когда мутабельность не имеет смысла. Таким образом, Arc<str> побеждает во всех случаях. Он эффективнее, и на него легко перейти.
Vec<T> and String
Почему же не использовать Vec<T> или String? Здесь стоит оговориться — я уже намекал, но сейчас скажу явно, что Vec<T> и String — для модификации. Для добавления и удаления, расширения и укорачивания данных. И если вам это не требуется, не используйте их, потому что они имеют дополнительную плату за то, что дают:
fn push(&mut self, ch: char) fn extend<I>(&mut self, iter: I) fn pop(&mut self) -> Option<char> fn retain<F>(&mut self, f: F) fn truncate(&mut self, new_len: usize) fn reserve(&mut self, additional: usize) fn resize(&mut self, new_len: usize, value: T) fn drain<R>(&mut self, range: R) -> Drain<'_, T, A> fn clear(&mut self) fn shrink_to_fit(&mut self) Все эти методы Vec<T> и String интересны тем, что все они принимают &mut self, то есть модифицируют свои данные. Если вам не нужны эти фичи, не используйте Vec<T> и String.
Если вам просто нужно посмотреть на какие-то данные, вычислить их размер, узнать, не пуст ли буфер с данными, взять данные по индексу, проитерироваться по нему, разделить его, произвести в нем поиск — все эти вещи предоставляются непосредственно str и [T], оба из которых вы можете легко взять через Arc:
fn len(&self) -> usize fn is_empty(&self) -> bool fn get(&self, index: usize) -> Option<&T> fn iter(&self) -> Iter<'_, T> fn split_at(&self, mid: usize) -> (&[T], &[T]) fn strip_prefix<P>(&self, prefix: P) -> Option<&[T]> fn contains(&self, x: &T) -> bool fn binary_search(&self, x: &T) -> Result<usize, usize> fn to_vec(&self) -> Vec<T> fn repeat(&self, n: usize) -> Vec<T> impl<T, I> Index<I> for [T] impl<T> ToOwned for [T] impl<T> Eq for [T] Итак, вам не нужна вся мощь String и Vec<T>, если вам нужны только read-only операции, и вы можете выиграть в производительности, просто не платя за String и Vec<T>. Именно поэтому вы могли бы рассмотреть использование Arc<[T]> вместо Vec<T> или Arc<str> вместо String.
Arc<String>
Теперь, я хочу показать вам Arc<String>, поскольку я упоминал, что он плох, и вот почему. Arc<String> начинается точно так же, как и String, с буфера с текстом и некоторого дополнительного резервного места:

но потом мы так же должны положить саму String внутрь Arc:
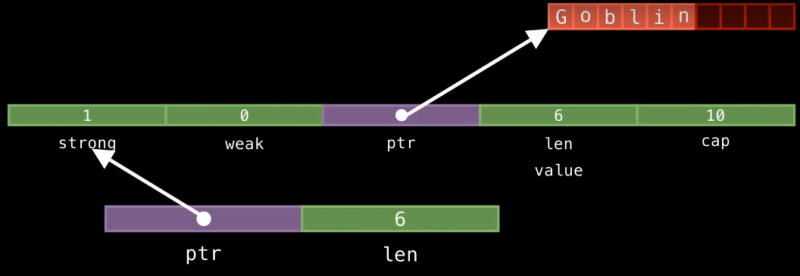
Итак, вы видите, что в начале у нас есть два поля для подсчета ссылок, потом идут данные объекта String. Объект Arc будет указывать на эти данные, а копирование будет копировать ссылку на String. Но если нам захочется достучаться до текстовых данных “Goblin,” нам придется прыгнуть на String, а затем прыгнуть со String на “Goblin”, и все эти манипуляции просто громоздки и неудобны, поэтому Arc<String> — это плохая идея, когда мы можем просто использовать Arc<str>.
Box<str>
Наконец, я упоминал, что если вам не нужно копирование, вы можете пойти еще дальше и использовать Box<str> вместо Arc<str>, и это, в сущности, будет настолько эффективно, насколько это вообще возможно, если исходить из предположения, что вам не нужно копирование объекта.

Тут нет лишней зарезервированной памяти, Box просто выделяет необходимые данные в куче, ссылается на них и знает, какого они размера. Вероятно, нельзя сделать еще лучше, чем этот вариант, однако, когда вы будете копировать такой объект, вы будете делать deep clone всех данных на куче.
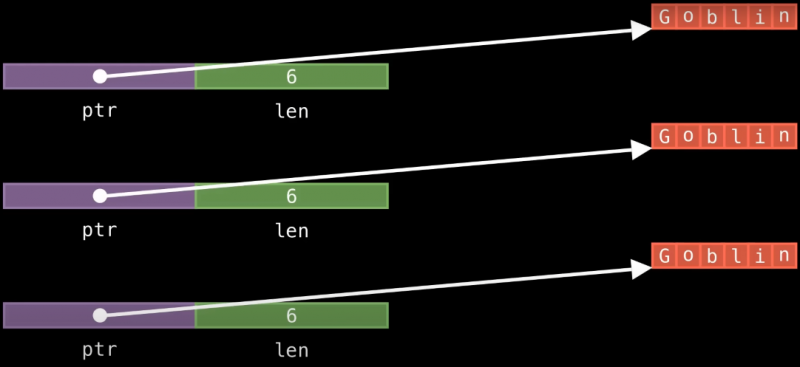
Но если ваши данные не поддерживают Clone, то это лучший вариант в плане эффективности по занимаемой памяти. Так что рассмотрите Box<str>, если это ваш случай.
Послесловие от переводчика
В тот момент, когда я решил переводить данное видео от Logan Smith, алгоритмы YouTube подкинули мне реакцию ThePrimeagen на это самое видео. Эта реакция оказалась примечательна тем, что ThePrimeagen задался справедливым и, возможно, всплывшим у некоторых читателей вопросом: “А как вообще создать или инициализировать Arc<str>?”.
И действительно, мы привыкли к тому, что имеем дело с типом &str — не str. Что такое в сущности strи как его создать, как с ним работать? В документации про тип str написано следующее:
The
strtype, also called a ‘string slice’, is the most primitive string type. It is usually seen in its borrowed form,&str. It is also the type of string literals,&'static str.
Окей, str — это “срез строки”, и в чистом виде его достаточно трудно уловить, поскольку при объявлении голой не-owned строки она будет иметь тип &str, не str:
let hello_world = "Hello, World!"; // тип &str Это сбило с толку и ThePrimeagen в том числе, и он ошибочно предположил, что Arc<str> можно создать только из строк, известных на этапе компиляции, например:
let s: &'static str = "Hello, World!"; let arc_str: Arc<str> = Arc::from(s); Но к его удивлению, точно таким же образом сработал и код формирующий Arc<str> из String:
let s = String::from("Hello, World!"); let arc_str: Arc<str> = Arc::from(s); Все потому, что для Arc реализован ряд трейтов, который под капотом делает всю магию за нас. В частности, это трейты:
-
impl From<String> for Arc<str>, у которого есть методfn from(v: String) -> Arc<str> -
impl From<&str> for Arc<str>, у которого есть методfn from(v: &str) -> Arc<str> -
impl<T, A> From<Vec<T, A>> for Arc<[T], A>, у которого есть методfn from(v: Vec<T, A>) -> Arc<[T], A>
Их имплементация позволяет удобно создавать Arc со всеми типами данных, упомянутыми в статье:
// from String let unique: String = "eggplant".to_owned(); let shared: Arc<str> = Arc::from(unique); assert_eq!("eggplant", &shared[..]); // from &str let shared: Arc<str> = Arc::from("eggplant"); assert_eq!("eggplant", &shared[..]); // from Vec<i32> let unique: Vec<i32> = vec![1, 2, 3]; let shared: Arc<[i32]> = Arc::from(unique); assert_eq!(&[1, 2, 3], &shared[..]);