Джон Мюллер из Google дает просветительский ответ о влиянии блокировки Google на «силу связей».
Джона Мюллера Google’ в подкасте SEO Office Hours спросили, приведет ли блокировка сканирования веб-страницы к отмене “мощности связывания” внутренних или наружных ссылок. Его ответ предложил неожиданный способ взглянуть на проблему и дает понять, как Google Search внутренний подход к этой и другим ситуациям.
О силе ссылок
Существует много способов думать о ссылках, но с точки зрения внутренних ссылок Google постоянно говорит об использовании внутренних ссылок, чтобы сообщать Google, какие страницы являются важнейшими.
В последнее время Google не обнародовал никаких патентов или исследовательских статей о том, как они используют внешние ссылки для рейтинга веб-страниц, поэтому почти все, что специалисты по оптимизации знают о внешних ссылках, базируется на старой информации, которая может быть открыта в текущей дате .
То, что сказал Джон Мюллер, ничего не добавляет к нашему пониманию того, как Google использует входящие или внутренние ссылки, но предлагает другой способ думать о них, который, на мой взгляд, полезнее его кажется на первый взгляд.
Влияние на ссылку через блокировку индексирования
Человек, задающий вопрос, хотел знать, повлияло ли блокирование Google на сканирование веб-страницы на то, как внутренние и входящие ссылки используются Google.
Этот вопрос:
“Или блокирование сканирования или индексирование URL-адреса отменяет силу ссылок внешних и внутренних ссылок?”
Мюллер предлагает найти ответ на вопрос, подумав о том, как бы на него отреагировал пользователь, что является интересным ответом, но также содержит интересное понимание.
Он ответил:
“Я’посмотрел бы на это как пользователь. Если страница недоступна для них, они не смогут ничего с ней сделать, и поэтому любые ссылки на этой странице будут несколько нерелевантными.
Приведенное выше согласуется с тем, что мы знаем о связи между сканированием, индексированием и ссылками. Если Google не может просканировать ссылку, Google не увидит ссылку, и поэтому ссылка не будет иметь эффекта.
Предложение Мюллера смотреть на это так, как на это смотрел бы пользователь, интересно, поскольку это не так, как большинство людей воспримут вопросы, связанные со ссылкой. Но это имеет смысл, потому что если вы заблокируете человеку доступ к веб-страницы, он не сможет увидеть ссылку, так ?
Что касается внешних ссылок? Давно-давно я увидел платную ссылку на веб-сайт с чернилами для принтеров, которая была на веб-странице морской биологии о чернилах осьминога. Тогдашние разработчики ссылок считали, что если веб-страница содержит слова, соответствующие целевой странице (осьминог “чернила” к принтеру “чернила”), то Google будет использовать эту ссылку для рейтинга потому что ссылка была на “релевантной” веб-страница.
Как бы тупо это ни звучало сегодня, многие верили в эту “основу на ключевом слове” подход к пониманию ссылок в отличие от подхода, ориентированного на пользователя, предлагаемого Джоном Мюллером. Если смотреть с точки зрения пользователя, то понять ссылку становится гораздо легче и, скорее всего, лучше согласуется с тем, как Google оценивает ссылку, чем старомодный подход на основе ключевых слов.
Оптимизируйте ссылки, сделав их доступными для сканирования
Мюллер продолжил свой ответ, отмечая важность того, чтобы страницы были доступны с помощью ссылок.
Он объяснил:
“Если вы хотите, чтобы страницу было легко найти, убедитесь, что на ней есть ссылки со страниц, которые можно индексировать и релевантные на вашем веб-сайте. Можно также заблокировать индексирование страниц, которые вы не хотите, чтобы их обнаруживали, это, в конце концов, вы решаете, но если на важную часть вашего веб-сайта есть только ссылки с заблокированной страницы, то это значительно усложнит поиск.”
О блокировке сканирования
Последнее слово о блокировке поисковых систем сканирования веб-страниц. Удивительно распространенное заблуждение некоторых владельцев сайтов заключается в том, что они используют мета-директиву robots, чтобы приказать Google не индексировать веб-страницу, а сканировать ссылки на веб-странице.
(ложная) директива выглядит так:
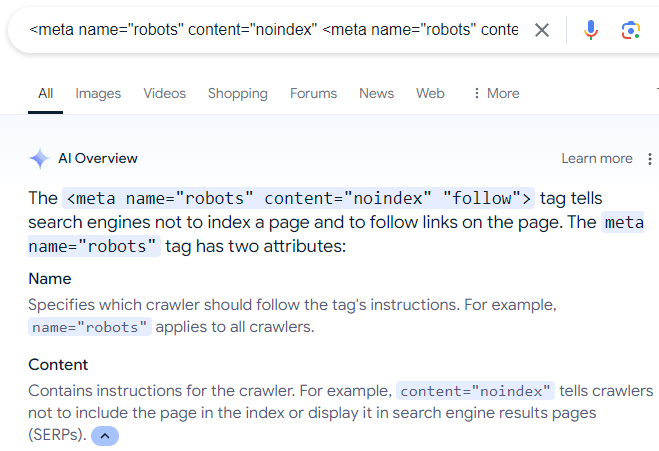
&met;meta name=”robots” content=”noindex” <meta name=”работы” content=”noindex” “следовать”>
Есть много дезинформации в Интернете, которая рекомендует вышеуказанное метаописание, которое даже отображено в Google&aa;s AI Overviews:
Снимок экрана обзоров AI
Конечно, приведенная выше директива роботов не работает, потому что, как объясняет Мюллер, если человек (или поисковая система) не может увидеть веб-страницу, то это лицо (или поисковая система) не может перейти по ссылкам , которые находятся на веб-странице.
Кроме того, пока существует “nofollow” директивное правило, которое можно использовать, чтобы сканер поисковой системы игнорировал ссылку на веб-страницы нет “следить” директива, которая заставляет сканер поисковой системы сканировать все ссылки на веб-странице. Переход по ссылкам является стандартным, который поисковая система может решить самостоятельно.
Подробнее о метатегах robots.
Послушайте ответ Джона Мюллера на вопрос с 14:45 минуты подкаста: